
Redis 集群
什么是 Redis 集群
之前我们讲到 Redis 哨兵机制,它主要用于提高 Redis 主从复制结构的高可用性,能够在主节点出现故障时自动进行故障转移,保证集群的持续可用性。然而,哨兵机制并不能解决数据分片和扩展性的问题。为了解决这些问题,Redis 提供了集群(Cluster)机制。Redis 集群允许将数据分布在多个节点上,实现数据的分片存储,从而提高系统的扩展性和性能。
Redis 集群通过将数据分片存储在多个节点上,实现了水平扩展。每个节点负责存储一部分数据,并且节点之间可以相互通信,以确保数据的一致性和完整性。Redis 集群使用一种称为哈希槽(hash slot)的机制来管理数据的分布。整个键空间被划分为 16384 个哈希槽,每个键通过哈希函数映射到一个哈希槽,然后该哈希槽被分配给某个节点进行存储。
下面是 Redis 集群的概览图:
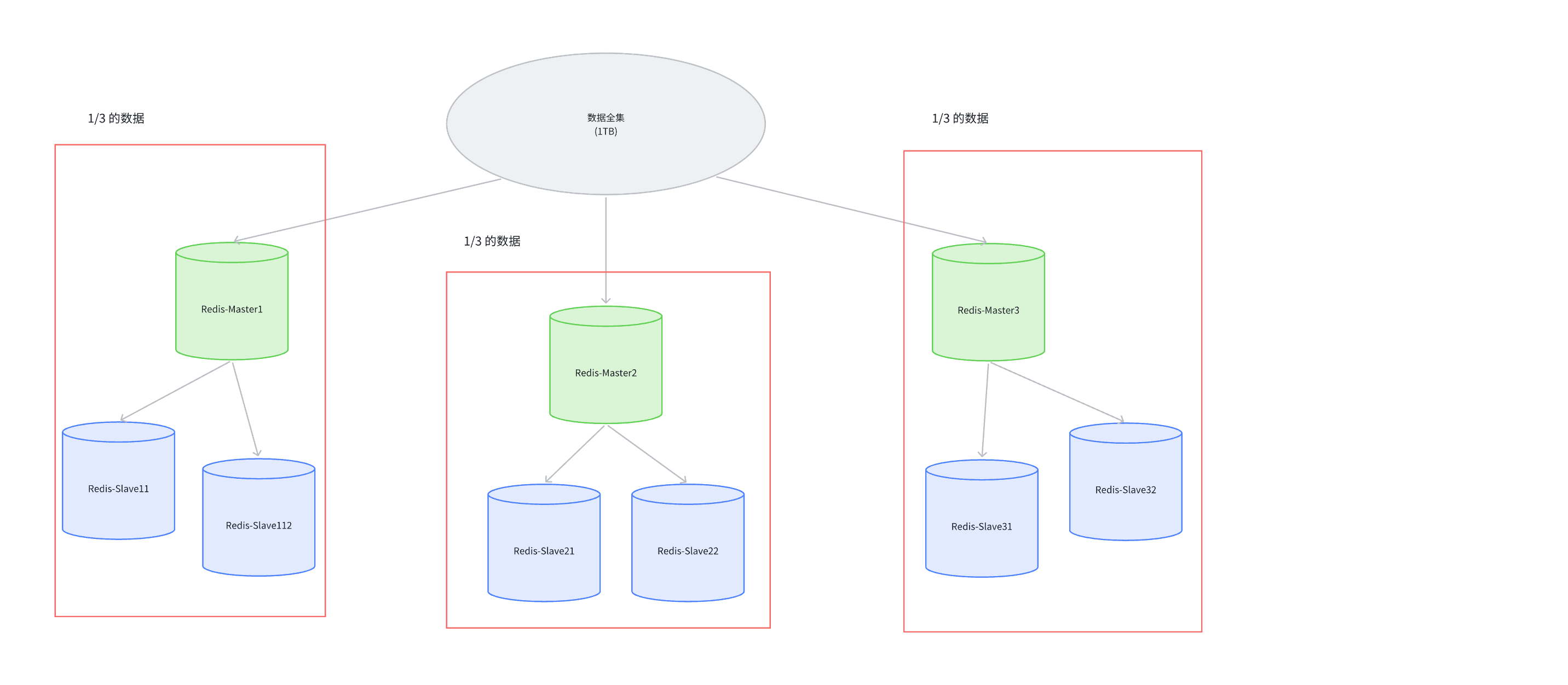
在上述图中:
- Master1 和 Slave11 和 Slave12 保存的是同样的数据. 占总数据的 1/3
- Master2 和 Slave21 和 Slave22 保存的是同样的数据. 占总数据的 1/3
- Master3 和 Slave31 和 Slave32 保存的是同样的数据. 占总数据的 1/3
这三组机器的存储数据是不一样的. 这样就实现了数据的分片存储.
每个 Slave 都是对应 Master 的备份,当主节点挂了,Slave 会自动提升为 Master,保证数据的高可用性。
每个红框部分都可以成为是一个分片,每个分片都可以独立工作,互不影响。
如果全量数据进一步增大,可以通过增加分片的方式来扩展集群的存储能力。
分片机制让每一个节点都承担了自己的一部分责任,这样使得即便有某一个集群组完全挂掉了,所影响到的也只是那一部分的数据,因此集群的健壮性比哨兵要强不少,而集群本身就包含了哨兵机制,所以在资源管理过于繁忙且服务器资源足够的情况下,更推荐通过 Redis 集群来作为生产环境的工具。
下面是哨兵和集群的对比图:
graph TD
subgraph SentinelMode[哨兵模式]
S_Master[主节点
写入/读取]
S_Slave1[从节点1
读取/备份]
S_Slave2[从节点2
读取/备份]
S_Sentinel1[Sentinel1]
S_Sentinel2[Sentinel2]
S_Sentinel3[Sentinel3]
S_Master -.-> S_Slave1
S_Master -.-> S_Slave2
S_Sentinel1 -.监控.-> S_Master
S_Sentinel2 -.监控.-> S_Master
S_Sentinel3 -.监控.-> S_Master
end
subgraph ClusterMode[集群模式]
C_Shard1[分片1
主节点]
C_Shard1_Slave[分片1从节点]
C_Shard2[分片2
主节点]
C_Shard2_Slave[分片2从节点]
C_Shard3[分片3
主节点]
C_Shard3_Slave[分片3从节点]
C_Shard1 -.-> C_Shard1_Slave
C_Shard2 -.-> C_Shard2_Slave
C_Shard3 -.-> C_Shard3_Slave
C_Shard1 -- 集群总线 --> C_Shard2
C_Shard2 -- 集群总线 --> C_Shard3
C_Shard3 -- 集群总线 --> C_Shard1
end
classDef master fill:#ff9999,stroke:#333
classDef slave fill:#99ccff,stroke:#333
classDef sentinel fill:#ccffcc,stroke:#333
classDef shard fill:#ffcc99,stroke:#333
class S_Master,S_Slave1,S_Slave2 master,slave
class S_Sentinel1,S_Sentinel2,S_Sentinel3 sentinel
class C_Shard1,C_Shard2,C_Shard3 shard
class C_Shard1_Slave,C_Shard2_Slave,C_Shard3_Slave slave
可以看到,集群虽然也用到了主从复制和哨兵机制,但它的核心在于数据的分片存储和节点间的通信,这使得集群在处理大规模数据和高并发请求时表现得更加出色。且哨兵机制的实现实际是让多个主节点互相监控,而不是单一主节点被多个哨兵监控。
数据分片算法
在正式讲解 Redis 所采用的分片算法之前,我们先了解一下两个前置的分片算法:
哈希求余法
哈希求余法是最简单的分片算法。它通过对键进行哈希计算(一般使用 MD5 或 SHA1),然后对节点数量取模来确定数据存储在哪个节点上。具体步骤如下:
- 对键进行哈希计算,得到一个哈希值。
- 将哈希值对节点数量取模,得到一个节点索引。
- 将数据存储到对应的节点上。
这种方法的优点是实现简单,分布均匀,但缺点是当节点数量发生变化时,可能会导致大量数据迁移。
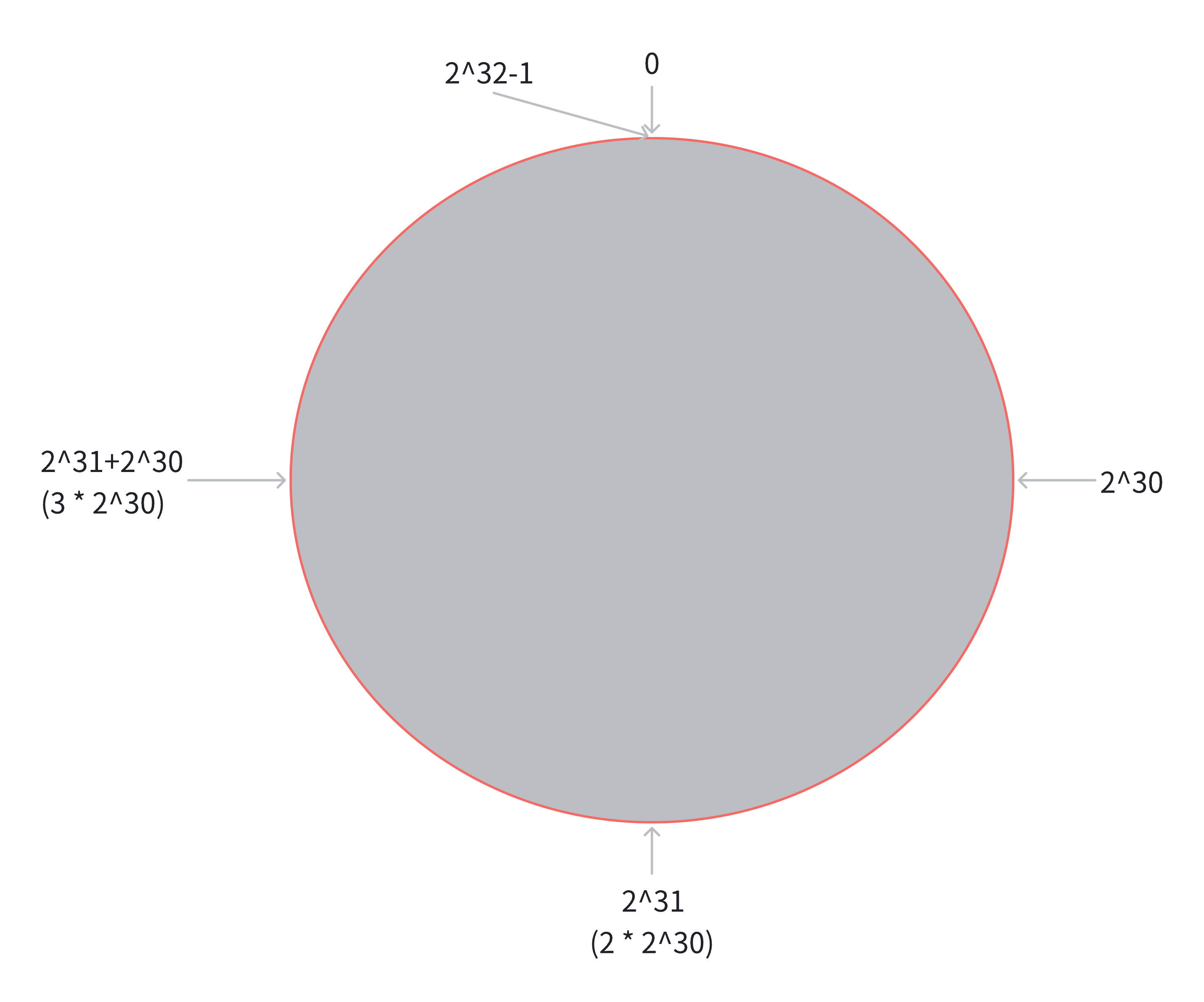
我们来举一个例子:

如上图示例,我们起初是将数据均匀分布到三个分片上面,当我们将分片扩容到四个分片的时候,原本在分片 3 上面的数据就会被重新分配到其他的分片上面,且被迁移的数量是非常庞大的,这就导致了系统的低效。
一致性哈希算法
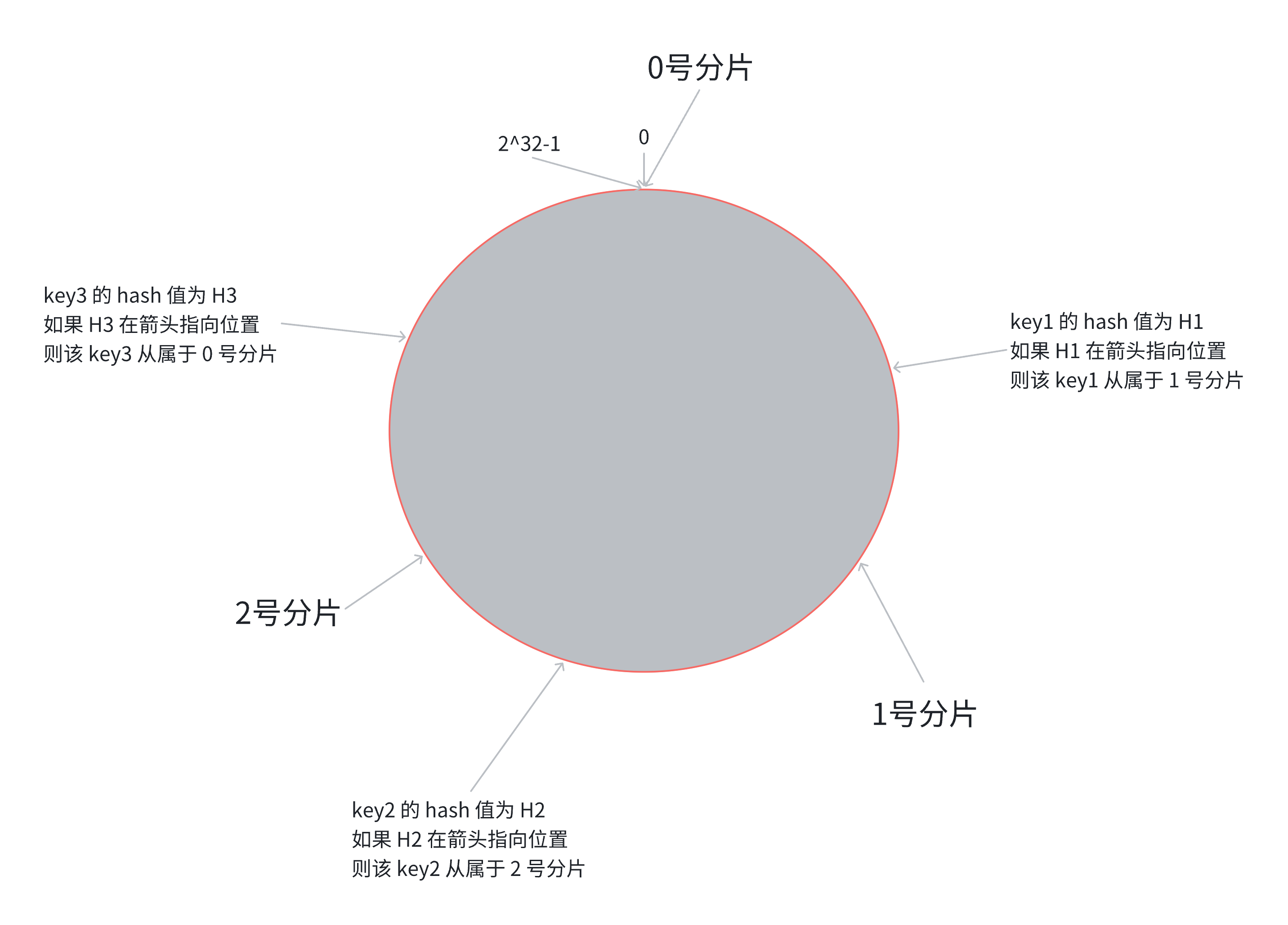
一致性哈希算法是一种改进的分片算法,旨在减少节点变化时的数据迁移量。它通过将节点和数据映射到一个虚拟的环上来实现分片。具体步骤如下:
- 将所有节点映射到一个虚拟的哈希环上。
- 假设当前存在三个分片,就把分片放到圆环的某个位置上。
- 对每个数据项进行哈希计算,找到它在环上的位置。
- 将数据项存储到顺时针方向第一个节点上。
这种方法的优点是,当节点增加或减少时,只需要对环上的一部分数据进行迁移,从而大大减少了数据迁移的量。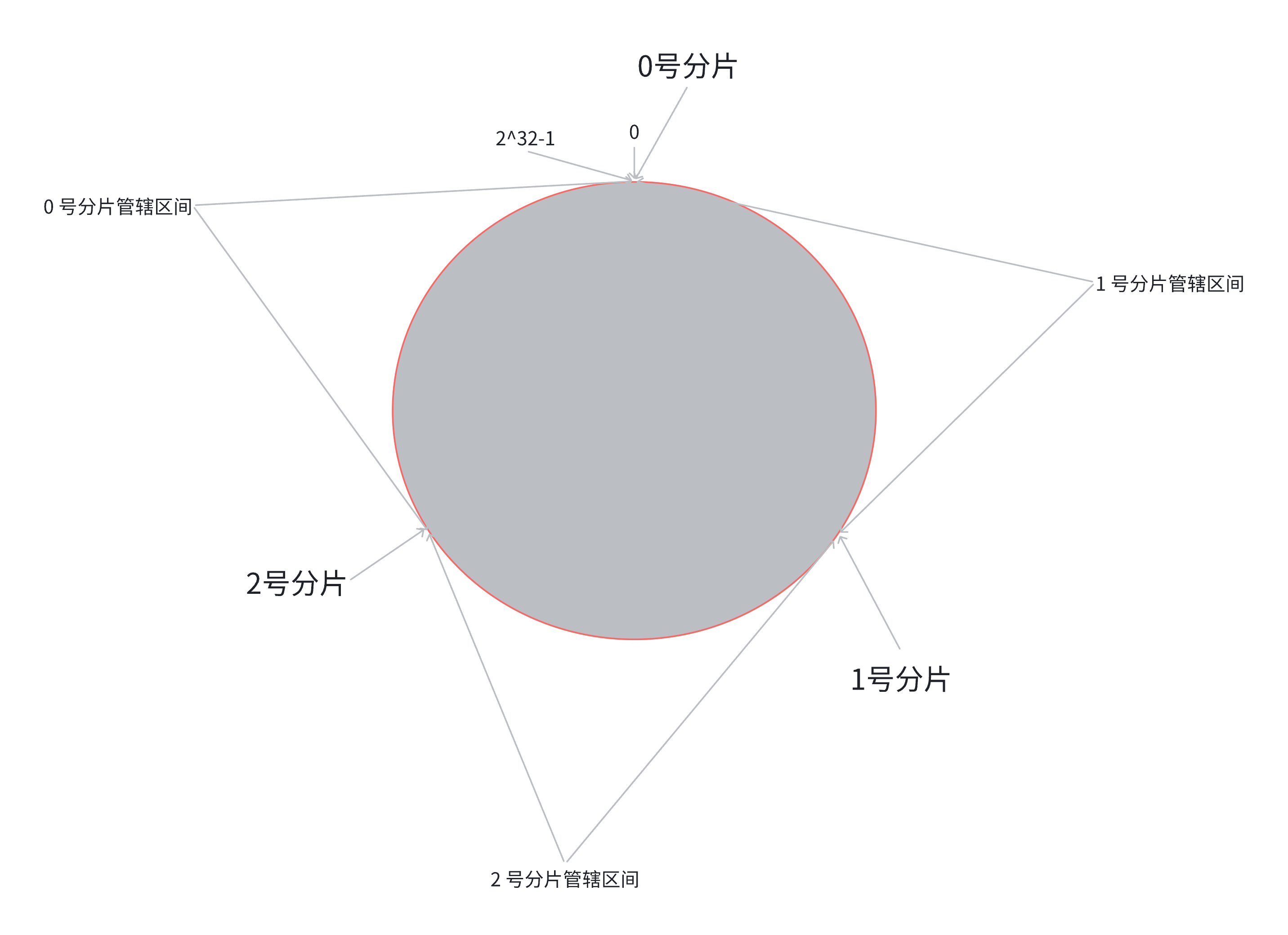
下面我们假设要将分片数量扩展到四个分片,我们只需要将新增的分片放到环上的某个位置上,然后顺时针方向将数据重新分配到新的节点上即可。可以看到,只有一部分数据被重新分配,其他数据仍然保持不变。
可以看到,只有(100/2/3)%的数据被重新分配,其他数据仍然保持不变。
当然,缺点也非常明显,一致性哈希算法的实现相对复杂,且在节点数量较少时,可能会导致数据分布不均匀。如果说我们想让他分配均匀,也不是不行,我们可以插入当前分片数个分片的虚拟节点,这样就能让数据分布均匀,但同时需要修改将近 50% 的数据,不过即便如此,修改的数据量也比哈希求余法要少很多。
Redis 集群的分片算法–哈希槽分区算法
为了解决上述问题(搬运成本高 和 数据分布不均匀),Redis 集群引入了哈希槽分区算法。
哈希槽(hash slot)分片算法,整个键空间被划分为 16384 个哈希槽,每个键通过哈希函数映射到一个哈希槽,然后该哈希槽被分配给某个节点进行存储。具体步骤如下:
- 对键进行哈希计算,得到一个哈希值。
- 将哈希值对 16384 取模,得到一个哈希槽索引。
- 将数据存储到对应的哈希槽所在的节点上。
假设当前有三个分配,一种可能的分配方式如下:
- 分片 1:负责哈希槽 [0, 5461],共 5462 个槽
- 分片 2:负责哈希槽 [5462, 10922],共 5461 个槽
- 分片 3:负责哈希槽 [10923, 16383],共 5461 个槽
需要注意的是,这里的分片规则非常灵活,并不是说每一个分片分得的哈希槽得是一块完全连续的区域,我们可以将哈希槽打散分配到各个分片上面去,这样就能更均匀的分配数据。
当我们需要扩展分片时,比如从 3 个分片扩展到 4 个分片,我们只需要将部分哈希槽重新分配给新的分片即可。
一种可能的分配方式如下:
- 分片 1:负责哈希槽 [0, 4095],共 4096 个槽
- 分片 2:负责哈希槽 [5462, 9557],共 4096 个槽
- 分片 3:负责哈希槽 [10924, 15019],共 4096 个槽
- 分片 4:负责哈希槽 [4096, 5461] 和 [9558, 10922] 和 [15020, 16383],共 4096 个槽
可以看到,我们仅改动了 25% 的哈希槽,其他 75% 的哈希槽保持不变,这样就大大减少了数据迁移的量。且 25% 是绝对最优的哈希槽分配方案,因为分片 4 必须要分配到 4096 个哈希槽,所以至少要从其他分片中拿出 25% 的哈希槽。
Redis 利用位图来存储每个节点负责的哈希槽,这样可以高效地进行哈希槽的查找和分配。
客户端在没有集群信息的情况下,可以通过向任意节点发送请求来获取集群的哈希槽分配信息,从而知道每个键应该存储在哪个节点上。
具体流程如下:
- 客户端向任意节点发送请求。
- 该节点返回集群的哈希槽分配信息。
- 客户端缓存该槽位的节点映射信息。
- 客户端根据哈希槽分配信息,将请求路由到正确的节点。
而具体到分片的管辖上,分片在接收到任意一个请求后,都会先计算出该请求对应的哈希槽,然后查看自己是否负责该哈希槽,如果不是,该切片会自动将该请求重定向到负责该哈希槽的切片上。
flowchart TD
A[客户端发送请求] --> B[服务端接收请求]
B --> C[计算键的哈希槽]
C --> D{槽位是否属于当前节点?}
D -->|是| E[执行命令并返回结果]
D -->|否| F[返回MOVED错误
包含正确节点地址]
F --> G[客户端接收MOVED错误]
G --> H[客户端更新本地路由表缓存]
H --> I[客户端重新向正确节点发送请求]
I --> J[正确节点执行命令]
E --> K[请求完成]
J --> K
从而保证了分片映射信息不会被客户端缓存过久,导致请求发送错误,且如果直接将缓存信息发送给客户端,一方面增加了网络开销,另一方面也增加了客户端的复杂度,且这些信息本来就是分片的职责,不应该暴露给客户端。
Redis 的作者建议分片数量不应该超过 1000 个,且每个分片负责的哈希槽数量不应该少于 50 个,这样可以保证数据的均匀分布和系统的高效运行。
为什么是 16384 个哈希槽呢?下面是原作者的回答:
• Normal heartbeat packets carry the full configuration of a node, that can be replaced in anidempotent way with the old in order to update an old config. This means they contain theslots configuration for a node, in raw form, that uses 2k of space with 16k slots, but woulduse a prohibitive 8k of space using 65k slots.
• At the same time, it is unlikely that Redis Cluster would scale to more than 1000 masternodes because of other design tradeoffs.So 16k was in the right range to ensure enough slots per master with a max of 1000 masters, buta small enough number to propagate the slot configuration as a raw bitmap easily. Note that in small clusters, the bitmap would be hard to compress, because when N is small, the bitmapwould have slots/N bits set. That is a large percentage of bits set.
翻译过来大概意思是:
• 节点之间通过⼼跳包通信. ⼼跳包中包含了该节点持有哪些 slots. 这个是使用位图这样的数据结构表示的. 表示 16384 (16k) 个 slots, 需要的位图⼤⼩是 2KB. 如果给定的 slots 数更多了, 比如 65536 个了, 此时就需要消耗更多的空间, 8 KB 位图表示了. 8 KB, 对于内存来说不算什么, 但是在频繁的网络心跳包中, 还是一个不小的开销的.
• 另一方面, Redis 集群一般不建议超过 1000 个分片. 所以 16k 对于最大 1000 个分片来说是足够用的, 同时也会使对应的槽位配置位图体积不至于很大.
集群搭建实践(基于 Docker)
小编手上只有 3 台机器,不方便搭建集群,因此这里使用 Docker 来搭建一个 3 主 6 从的 Redis 集群。
集群拓扑图如下:
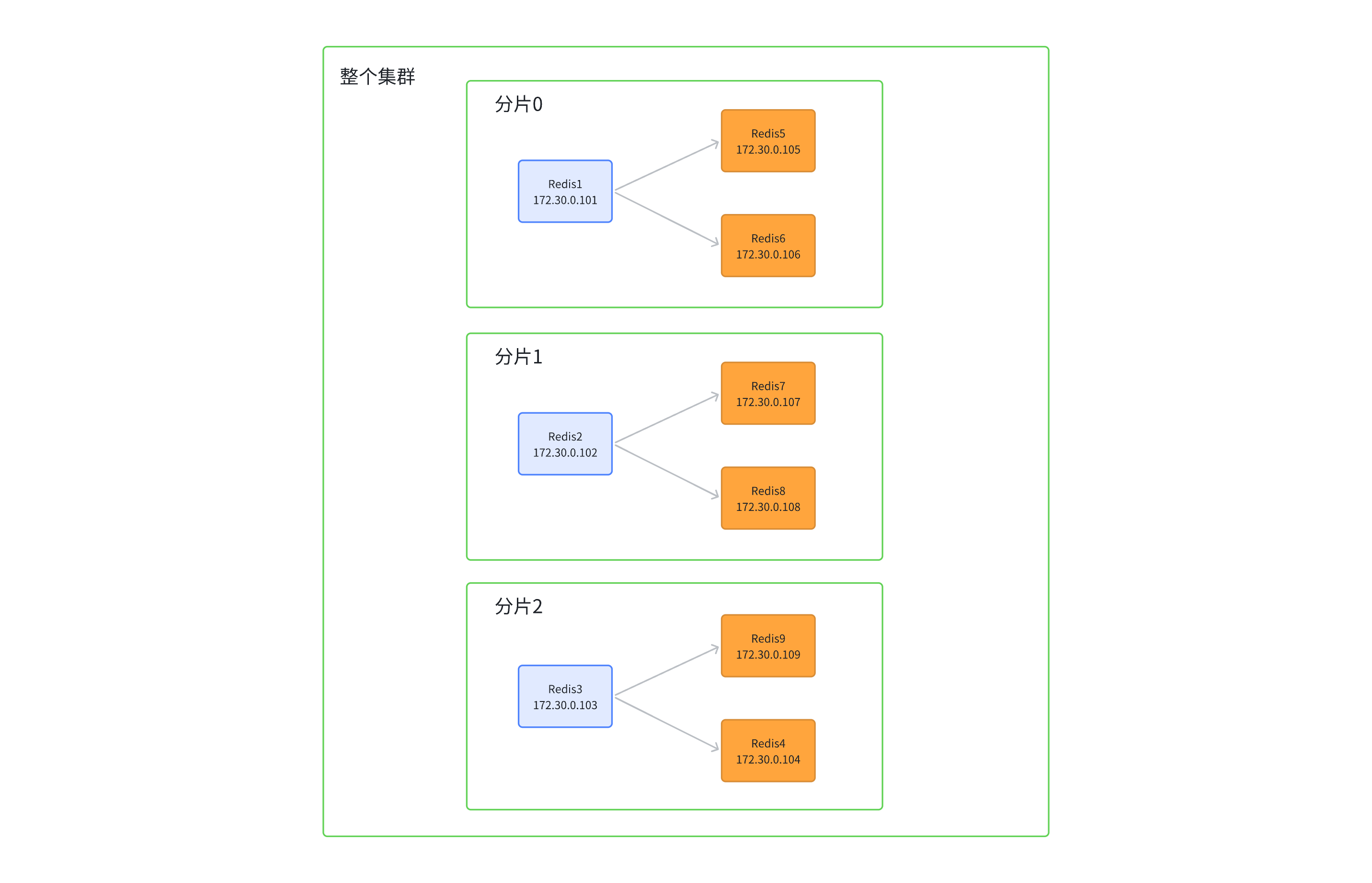
这里我们会先创建出 11 个 redis 节点,其中前 9 个节点会被用来创建集群,后两个用来演示集群扩容。
第一步:创建目录和配置
我们先在本地创建一个目录 redis-cluster,然后在该目录下创建 11 个子目录,分别对应 11 个 Redis 节点。
目录结构如下:
../redis-cluster
├── docker-compose.yml
└── generate.sh然后我们需要创建 11 个 Redis 配置文件,若通过手动创建的话,工作量会比较大,因此我们可以通过脚本来生成这些配置文件。
创建一个 generate.sh 脚本,内容如下:
for port in $(seq 1 9); do
mkdir -p redis${port}/
touch redis${port}/redis.conf
cat <<EOF >redis${port}/redis.conf
port 6379
bind 0.0.0.0
protected-mode no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 172.30.0.10${port}
cluster-announce-port 6379
cluster-announce-bus-port 16379
EOF
done
# cluster-announce-ip 的值有变化(10 和 11)
for port in $(seq 10 11); do
mkdir -p redis${port}/
touch redis${port}/redis.conf
cat <<EOF >redis${port}/redis.conf
port 6379
bind 0.0.0.0
protected-mode no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 172.30.0.1${port}
cluster-announce-port 6379
cluster-announce-bus-port 16379
EOF
done该脚本会创建 11 个目录 redis1 到 redis11,并在每个目录下生成一个 redis.conf 配置文件。需要注意的是,这里我们将 cluster-announce-ip 设置为 Docker 网络中的 IP 地址,确保每个节点能够相互通信。
配置说明:
port:指定 Redis 实例的端口号。bind:指定 Redis 实例监听的 IP 地址。protected-mode:设置为 no,表示关闭保护模式。appendonly:设置为 yes,表示开启 AOF 持久化。cluster-enabled:设置为 yes,表示开启集群模式。cluster-config-file:指定集群配置文件的名称。cluster-node-timeout:设置集群节点超时时间。cluster-announce-ip:指定集群节点的 IP 地址。cluster-announce-port:指定集群节点的端口号。cluster-announce-bus-port:指定集群节点的总线端口号,集群管理的信息交互是通过这个端口进行的。
执行该脚本后得到文件目录:
../redis-cluster
├── docker-compose.yml
├── generate.sh
├── redis
├── redis1
│ └── redis.conf
├── redis10
│ └── redis.conf
├── redis11
│ └── redis.conf
├── redis2
│ └── redis.conf
├── redis3
│ └── redis.conf
├── redis4
│ └── redis.conf
├── redis5
│ └── redis.conf
├── redis6
│ └── redis.conf
├── redis7
│ └── redis.conf
├── redis8
│ └── redis.conf
└── redis9
└── redis.conf第二步:创建 Docker Compose 文件
为了让这 11 个 Redis 节点能够互相通信,我们需要创建一个自定义的 Docker 网络,并分配网段为 172.30.0.0/24。
创建一个 docker-compose.yml 文件,内容如下:
networks:
mynet:
ipam:
config:
- subnet: 172.30.0.0/24
services:
redis1:
image: "redis:8.0.3"
container_name: redis1
restart: always
volumes:
- ./redis1/:/etc/redis/
ports:
- 6371:6379
- 16371:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.101
redis2:
image: "redis:8.0.3"
container_name: redis2
restart: always
volumes:
- ./redis2/:/etc/redis/
ports:
- 6372:6379
- 16372:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.102
redis3:
image: "redis:8.0.3"
container_name: redis3
restart: always
volumes:
- ./redis3/:/etc/redis/
ports:
- 6373:6379
- 16373:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.103
redis4:
image: "redis:8.0.3"
container_name: redis4
restart: always
volumes:
- ./redis4/:/etc/redis/
ports:
- 6374:6379
- 16374:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.104
redis5:
image: "redis:8.0.3"
container_name: redis5
restart: always
volumes:
- ./redis5/:/etc/redis/
ports:
- 6375:6379
- 16375:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.105
redis6:
image: "redis:8.0.3"
container_name: redis6
restart: always
volumes:
- ./redis6/:/etc/redis/
ports:
- 6376:6379
- 16376:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.106
redis7:
image: "redis:8.0.3"
container_name: redis7
restart: always
volumes:
- ./redis7/:/etc/redis/
ports:
- 6377:6379
- 16377:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.107
redis8:
image: "redis:8.0.3"
container_name: redis8
restart: always
volumes:
- ./redis8/:/etc/redis/
ports:
- 6378:6379
- 16378:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.108
redis9:
image: "redis:8.0.3"
container_name: redis9
restart: always
volumes:
- ./redis9/:/etc/redis/
ports:
- 6379:6379
- 16379:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.109
redis10:
image: "redis:8.0.3"
container_name: redis10
restart: always
volumes:
- ./redis10/:/etc/redis/
ports:
- 6380:6379
- 16380:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.110
redis11:
image: "redis:8.0.3"
container_name: redis11
restart: always
volumes:
- ./redis11/:/etc/redis/
ports:
- 6381:6379
- 16381:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.111该文件定义了 11 个 Redis 服务,每个服务都使用 redis:8.0.3 镜像,并挂载对应的配置文件目录。每个服务都暴露了两个端口,一个是 Redis 的默认端口 6379,另一个是集群总线端口 16379。
每个服务都连接到自定义的 mynet 网络,并分配了一个固定的 IP 地址,确保它们能够相互通信。
小编因为有一些端口正在跑后端服务,因此将该配置文件中的某些端口做了映射修改,比如 redis1 的 6379 端口映射到了宿主机的 6389 端口,不过这无伤大雅,因为这些端口是给外界使用的,而我们的所有操作都是基于容器网络内部环境进行操作的。如果你的机器上没有端口冲突的话,建议保持一致。
注意:这里的 IP 地址必须和配置文件中的
cluster-announce-ip保持一致,否则集群无法正常工作。配置文件的 ip 是告诉该节点自己的 ip 是多少,而 docker-compose.yml 中的 ip 是给予该节点使用该 ip 的权利,因此两者必须保持一致。
第三步:启动 Redis 实例
执行以下命令启动所有 Redis 实例:
╭─ljx@VM-16-15-debian ~/redistest/redis-cluster
╰─➤ docker compose up -d
[+] Running 12/12
✔ Network redis-cluster_mynet Created 0.1s
✔ Container redis2 Started 1.1s
✔ Container redis3 Started 1.4s
✔ Container redis10 Started 1.5s
✔ Container redis6 Started 1.2s
✔ Container redis4 Started 1.6s
✔ Container redis8 Started 0.9s
✔ Container redis1 Started 1.3s
✔ Container redis5 Started 1.5s
✔ Container redis7 Started 1.4s
✔ Container redis11 Started 0.7s
✔ Container redis9 Started可以通过以下命令查看所有容器的状态:
╭─ljx@VM-16-15-debian ~/redistest/redis-cluster
╰─➤ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
90961a014a90 redis:8.0.3 "docker-entrypoint.s…" 28 seconds ago Up 27 seconds 0.0.0.0:16379->16379/tcp, [::]:16379->16379/tcp, 0.0.0.0:6389->6379/tcp, [::]:6389->6379/tcp redis9
facfb4214c2a redis:8.0.3 "docker-entrypoint.s…" 28 seconds ago Up 27 seconds 0.0.0.0:6391->6379/tcp, [::]:6391->6379/tcp, 0.0.0.0:16381->16379/tcp, [::]:16381->16379/tcp redis11
5ab12a04a7db redis:8.0.3 "docker-entrypoint.s…" 28 seconds ago Up 27 seconds 0.0.0.0:6377->6379/tcp, [::]:6377->6379/tcp, 0.0.0.0:16377->16379/tcp, [::]:16377->16379/tcp redis7
92ba490d5c8d redis:8.0.3 "docker-entrypoint.s…" 28 seconds ago Up 27 seconds 0.0.0.0:6371->6379/tcp, [::]:6371->6379/tcp, 0.0.0.0:16371->16379/tcp, [::]:16371->16379/tcp redis1
46a704dfbf52 redis:8.0.3 "docker-entrypoint.s…" 28 seconds ago Up 27 seconds 0.0.0.0:6375->6379/tcp, [::]:6375->6379/tcp, 0.0.0.0:16375->16379/tcp, [::]:16375->16379/tcp redis5
eb367c18db29 redis:8.0.3 "docker-entrypoint.s…" 28 seconds ago Up 27 seconds 0.0.0.0:6390->6379/tcp, [::]:6390->6379/tcp, 0.0.0.0:16380->16379/tcp, [::]:16380->16379/tcp redis10
921ee573a2af redis:8.0.3 "docker-entrypoint.s…" 28 seconds ago Up 27 seconds 0.0.0.0:6374->6379/tcp, [::]:6374->6379/tcp, 0.0.0.0:16374->16379/tcp, [::]:16374->16379/tcp redis4
6e172ab4b1fb redis:8.0.3 "docker-entrypoint.s…" 28 seconds ago Up 27 seconds 0.0.0.0:6373->6379/tcp, [::]:6373->6379/tcp, 0.0.0.0:16373->16379/tcp, [::]:16373->16379/tcp redis3
d87b00443a7e redis:8.0.3 "docker-entrypoint.s…" 28 seconds ago Up 27 seconds 0.0.0.0:6372->6379/tcp, [::]:6372->6379/tcp, 0.0.0.0:16372->16379/tcp, [::]:16372->16379/tcp redis2
fbd4c5160350 redis:8.0.3 "docker-entrypoint.s…" 28 seconds ago Up 27 seconds 0.0.0.0:6378->6379/tcp, [::]:6378->6379/tcp, 0.0.0.0:16378->16379/tcp, [::]:16378->16379/tcp redis8
a681b450472e redis:8.0.3 "docker-entrypoint.s…" 28 seconds ago Up 27 seconds 0.0.0.0:6376->6379/tcp, [::]:6376->6379/tcp, 0.0.0.0:16376->16379/tcp, [::]:16376->16379/tcp redis6第四步:构建集群
我们启动其中的一个节点,进入该节点的容器:
docker exec -it redis1 bash
root@92ba490d5c8d:/data# redis-cli --cluster create 172.30.0.101:6379 172.30.0.102:6379 172.30.0.103:6379 172.30.0.104:6379 172.30.0.105:6379 172.30.0.106:6379 172.30.0.107:6379 172.30.0.108:6379 172.30.0.109:6379 --cluster-replicas 2
>>> Performing hash slots allocation on 9 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 172.30.0.105:6379 to 172.30.0.101:6379
Adding replica 172.30.0.106:6379 to 172.30.0.101:6379
Adding replica 172.30.0.107:6379 to 172.30.0.102:6379
Adding replica 172.30.0.108:6379 to 172.30.0.102:6379
Adding replica 172.30.0.109:6379 to 172.30.0.103:6379
Adding replica 172.30.0.104:6379 to 172.30.0.103:6379
M: ccaf61741c1209b3bb746480b84a0ea0c8cbb87c 172.30.0.101:6379
slots:[0-5460] (5461 slots) master
M: 3ba092a8b1547bcf2772b7da2b96f70805923f0f 172.30.0.102:6379
slots:[5461-10922] (5462 slots) master
M: 11f517397c7b986450d5ae213d0e19767944dc11 172.30.0.103:6379
slots:[10923-16383] (5461 slots) master
S: 61c77b70e815c201e56bbfc25c68cd6cbe367b8b 172.30.0.104:6379
replicates 11f517397c7b986450d5ae213d0e19767944dc11
S: 510e72ddb6afdb74f4a89d7eb021f8e80897c95e 172.30.0.105:6379
replicates ccaf61741c1209b3bb746480b84a0ea0c8cbb87c
S: f3734a1c3bc5520977ea9ace9c8894dd55b6efd4 172.30.0.106:6379
replicates ccaf61741c1209b3bb746480b84a0ea0c8cbb87c
S: 23b2ee4aa3170eec669af17284982b6da13e48d2 172.30.0.107:6379
replicates 3ba092a8b1547bcf2772b7da2b96f70805923f0f
S: 69fd461e80f8b2bc7d4c2856eb20039aed56b824 172.30.0.108:6379
replicates 3ba092a8b1547bcf2772b7da2b96f70805923f0f
S: 33de5344df9b7d89141d24292e91ec33d754a039 172.30.0.109:6379
replicates 11f517397c7b986450d5ae213d0e19767944dc11
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
.
>>> Performing Cluster Check (using node 172.30.0.101:6379)
M: ccaf61741c1209b3bb746480b84a0ea0c8cbb87c 172.30.0.101:6379
slots:[0-5460] (5461 slots) master
2 additional replica(s)
S: 69fd461e80f8b2bc7d4c2856eb20039aed56b824 172.30.0.108:6379
slots: (0 slots) slave
replicates 3ba092a8b1547bcf2772b7da2b96f70805923f0f
S: 61c77b70e815c201e56bbfc25c68cd6cbe367b8b 172.30.0.104:6379
slots: (0 slots) slave
replicates 11f517397c7b986450d5ae213d0e19767944dc11
S: 33de5344df9b7d89141d24292e91ec33d754a039 172.30.0.109:6379
slots: (0 slots) slave
replicates 11f517397c7b986450d5ae213d0e19767944dc11
M: 11f517397c7b986450d5ae213d0e19767944dc11 172.30.0.103:6379
slots:[10923-16383] (5461 slots) master
2 additional replica(s)
S: 510e72ddb6afdb74f4a89d7eb021f8e80897c95e 172.30.0.105:6379
slots: (0 slots) slave
replicates ccaf61741c1209b3bb746480b84a0ea0c8cbb87c
M: 3ba092a8b1547bcf2772b7da2b96f70805923f0f 172.30.0.102:6379
slots:[5461-10922] (5462 slots) master
2 additional replica(s)
S: 23b2ee4aa3170eec669af17284982b6da13e48d2 172.30.0.107:6379
slots: (0 slots) slave
replicates 3ba092a8b1547bcf2772b7da2b96f70805923f0f
S: f3734a1c3bc5520977ea9ace9c8894dd55b6efd4 172.30.0.106:6379
slots: (0 slots) slave
replicates ccaf61741c1209b3bb746480b84a0ea0c8cbb87c
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.这里我们使用 redis-cli --cluster create 命令来创建集群,指定了 9 个节点的 IP 地址和端口号,并通过 --cluster-replicas 2 参数指定每个主节点有 2 个从节点。
可以看到,当我们执行指令后,系统会自动为我们分配哈希槽,并将从节点分配给对应的主节点并让我们确认该配置是否符合你的预期,用户交互界面非常友好。最后系统会进行集群检查,确保所有节点都正确配置并且哈希槽覆盖完整。
其中 M 表示主节点(Master),S 表示从节点(Slave)。可以看到,集群已经成功创建。
我们进入任意一个节点,执行 cluster nodes 命令查看集群状态(我仍然在刚才的那个节点待着,并没有跑出来):
root@92ba490d5c8d:/data# redis-cli -h 172.30.0.101 -p 6379 -c
172.30.0.101:6379> cluster nodes
69fd461e80f8b2bc7d4c2856eb20039aed56b824 172.30.0.108:6379@16379 slave 3ba092a8b1547bcf2772b7da2b96f70805923f0f 0 1758424907569 2 connected
61c77b70e815c201e56bbfc25c68cd6cbe367b8b 172.30.0.104:6379@16379 slave 11f517397c7b986450d5ae213d0e19767944dc11 0 1758424907000 3 connected
33de5344df9b7d89141d24292e91ec33d754a039 172.30.0.109:6379@16379 slave 11f517397c7b986450d5ae213d0e19767944dc11 0 1758424906000 3 connected
11f517397c7b986450d5ae213d0e19767944dc11 172.30.0.103:6379@16379 master - 0 1758424908072 3 connected 10923-16383
510e72ddb6afdb74f4a89d7eb021f8e80897c95e 172.30.0.105:6379@16379 slave ccaf61741c1209b3bb746480b84a0ea0c8cbb87c 0 1758424907000 1 connected
3ba092a8b1547bcf2772b7da2b96f70805923f0f 172.30.0.102:6379@16379 master - 0 1758424906362 2 connected 5461-10922
23b2ee4aa3170eec669af17284982b6da13e48d2 172.30.0.107:6379@16379 slave 3ba092a8b1547bcf2772b7da2b96f70805923f0f 0 1758424906865 2 connected
ccaf61741c1209b3bb746480b84a0ea0c8cbb87c 172.30.0.101:6379@16379 myself,master - 0 0 1 connected 0-5460
f3734a1c3bc5520977ea9ace9c8894dd55b6efd4 172.30.0.106:6379@16379 slave ccaf61741c1209b3bb746480b84a0ea0c8cbb87c 0 1758424907368 1 connected可以看到,集群中有 3 个主节点和 6 个从节点,且每个主节点都有 2 个从节点,且会显示我们当前所在的节点(myself 标记)。
需要注意的是,这里我们使用了 -c 参数来启用集群模式,这样在执行命令时,客户端会自动处理重定向。举一个简单例子:
172.30.0.101:6379> set k1 1
-> Redirected to slot [12706] located at 172.30.0.103:6379
OK
172.30.0.103:6379>当前我们在 172.30.0.101:6379,我们执行 set k1 1 命令后,客户端会自动将请求重定向到负责该键的节点 172.30.0.103:6379。
这里的重定向机制我们上面有讲到过,客户端会先计算出该键对应的哈希槽,然后查看自己是否负责该哈希槽,如果不是,该节点会返回一个 MOVED 错误,告诉客户端正确的节点地址,客户端接收到该错误后,会更新本地的路由表缓存,然后重新向正确的节点发送请求。
主节点宕机测试
模拟主节点宕机
我们可以通过停止某个主节点的容器来模拟主节点宕机的场景。
这里我们手动停止 redis1 容器:
╭─ljx@VM-16-15-debian ~/redistest/redis-cluster
╰─➤ docker stop redis1
redis1
╭─ljx@VM-16-15-debian ~/redistest/redis-cluster
╰─➤ docker exec -it redis2 bash
root@d87b00443a7e:/data# redis-cli -h 172.30.0.102 -p 6379 -c
172.30.0.102:6379> cluster nodes
33de5344df9b7d89141d24292e91ec33d754a039 172.30.0.109:6379@16379 slave 11f517397c7b986450d5ae213d0e19767944dc11 0 1758425196061 3 connected
69fd461e80f8b2bc7d4c2856eb20039aed56b824 172.30.0.108:6379@16379 slave 3ba092a8b1547bcf2772b7da2b96f70805923f0f 0 1758425197569 2 connected
ccaf61741c1209b3bb746480b84a0ea0c8cbb87c 172.30.0.101:6379@16379 master,fail - 1758425121844 1758425119331 1 connected
23b2ee4aa3170eec669af17284982b6da13e48d2 172.30.0.107:6379@16379 slave 3ba092a8b1547bcf2772b7da2b96f70805923f0f 0 1758425196000 2 connected
f3734a1c3bc5520977ea9ace9c8894dd55b6efd4 172.30.0.106:6379@16379 master - 0 1758425196000 10 connected 0-5460
510e72ddb6afdb74f4a89d7eb021f8e80897c95e 172.30.0.105:6379@16379 slave f3734a1c3bc5520977ea9ace9c8894dd55b6efd4 0 1758425197770 10 connected
3ba092a8b1547bcf2772b7da2b96f70805923f0f 172.30.0.102:6379@16379 myself,master - 0 0 2 connected 5461-10922
11f517397c7b986450d5ae213d0e19767944dc11 172.30.0.103:6379@16379 master - 0 1758425197000 3 connected 10923-16383
61c77b70e815c201e56bbfc25c68cd6cbe367b8b 172.30.0.104:6379@16379 slave 11f517397c7b986450d5ae213d0e19767944dc11 0 1758425197000 3 connected可以看到,redis1 节点的状态变成了 fail,表示该节点已经宕机。
当我们重启 redis1 容器后:
172.30.0.102:6379> cluster nodes
33de5344df9b7d89141d24292e91ec33d754a039 172.30.0.109:6379@16379 slave 11f517397c7b986450d5ae213d0e19767944dc11 0 1758425335000 3 connected
69fd461e80f8b2bc7d4c2856eb20039aed56b824 172.30.0.108:6379@16379 slave 3ba092a8b1547bcf2772b7da2b96f70805923f0f 0 1758425335583 2 connected
ccaf61741c1209b3bb746480b84a0ea0c8cbb87c 172.30.0.101:6379@16379 slave f3734a1c3bc5520977ea9ace9c8894dd55b6efd4 0 1758425335683 10 connected
23b2ee4aa3170eec669af17284982b6da13e48d2 172.30.0.107:6379@16379 slave 3ba092a8b1547bcf2772b7da2b96f70805923f0f 0 1758425335583 2 connected
f3734a1c3bc5520977ea9ace9c8894dd55b6efd4 172.30.0.106:6379@16379 master - 0 1758425335583 10 connected 0-5460
510e72ddb6afdb74f4a89d7eb021f8e80897c95e 172.30.0.105:6379@16379 slave f3734a1c3bc5520977ea9ace9c8894dd55b6efd4 0 1758425335583 10 connected
3ba092a8b1547bcf2772b7da2b96f70805923f0f 172.30.0.102:6379@16379 myself,master - 0 0 2 connected 5461-10922
11f517397c7b986450d5ae213d0e19767944dc11 172.30.0.103:6379@16379 master - 0 1758425335000 3 connected 10923-16383
61c77b70e815c201e56bbfc25c68cd6cbe367b8b 172.30.0.104:6379@16379 slave 11f517397c7b986450d5ae213d0e19767944dc11 0 1758425334579 3 connected会发现,redis1 节点的状态变成了 slave,并且它现在是 f3734a1c3bc5520977ea9ace9c8894dd55b6efd4(redis6)的从节点。这说明在 redis1 宕机期间,redis6 被提升为了主节点,而当 redis1 重启后,它自动成为了 redis6 的从节点。
我们可以使用 cluster failover 命令进行集群恢复,也就是把 101 节点重新提升为主节点:
172.30.0.102:6379> cluster failover
(error) ERR You should send CLUSTER FAILOVER to a replica
172.30.0.102:6379> exit
root@d87b00443a7e:/data# redis-cli -h 172.30.0.101 -p 6379 -c
172.30.0.101:6379> cluster failover
OK
172.30.0.101:6379> cluster nodes
ccaf61741c1209b3bb746480b84a0ea0c8cbb87c 172.30.0.101:6379@16379 myself,master - 0 0 11 connected 0-5460
23b2ee4aa3170eec669af17284982b6da13e48d2 172.30.0.107:6379@16379 slave 3ba092a8b1547bcf2772b7da2b96f70805923f0f 0 1758425447000 2 connected
510e72ddb6afdb74f4a89d7eb021f8e80897c95e 172.30.0.105:6379@16379 slave ccaf61741c1209b3bb746480b84a0ea0c8cbb87c 0 1758425447558 11 connected
61c77b70e815c201e56bbfc25c68cd6cbe367b8b 172.30.0.104:6379@16379 slave 11f517397c7b986450d5ae213d0e19767944dc11 0 1758425445547 3 connected
33de5344df9b7d89141d24292e91ec33d754a039 172.30.0.109:6379@16379 slave 11f517397c7b986450d5ae213d0e19767944dc11 0 1758425446653 3 connected
3ba092a8b1547bcf2772b7da2b96f70805923f0f 172.30.0.102:6379@16379 master - 0 1758425446000 2 connected 5461-10922
f3734a1c3bc5520977ea9ace9c8894dd55b6efd4 172.30.0.106:6379@16379 slave ccaf61741c1209b3bb746480b84a0ea0c8cbb87c 0 1758425447659 11 connected
11f517397c7b986450d5ae213d0e19767944dc11 172.30.0.103:6379@16379 master - 0 1758425446000 3 connected 10923-16383
69fd461e80f8b2bc7d4c2856eb20039aed56b824 172.30.0.108:6379@16379 slave 3ba092a8b1547bcf2772b7da2b96f70805923f0f 0 1758425446553 2 connected若我们在其他节点上执行该操作,会发现报错,因为该命令只能在从节点上执行,而不能在主节点上执行。
故障处理流程
故障判定
集群的故障处理和自动恢复是通过 Gossip 协议和投票机制来实现的,他和哨兵机制类似,但不完全相同,因为集群节点数量非常多,所以需要更加高效的机制。以下是一般的故障处理流程:
心跳检测:节点 A 给节点 B 发送
ping包,B 就会给 A 返回一个pong包。ping和pong除了message type属性之外,其他部分都是一样的。这里包含了集群的配置信息(该节点的 id、该节点从属于哪个分片、是主节点还是从节点、从属于谁、持有哪些 slots 的位图…)。Gossip 协议:每个节点,每秒钟,都会给一些随机的节点发起
ping包,而不是全发一遍。这样设定是为了避免在节点很多的时候,心跳包也非常多(比如有 9 个节点,如果全发,就是 9 * 8 有 72 组心跳了,而且这是按照 N^2 这样的级别增长的)。主观下线(PFAIL):当节点 A 给节点 B 发起
ping包,B 不能如期回应的时候,此时 A 就会尝试重置和 B 的 TCP 连接,看能否连接成功。如果仍然连接失败,A 就会把 B 设为PFAIL状态(相当于主观下线)。信息传播:A 判定 B 为
PFAIL之后,会通过 Redis 内置的 Gossip 协议,和其他节点进行沟通,向其他节点确认 B 的状态。(每个节点都会维护一个自己的“下线列表”,由于视角不同,每个节点的下线列表也不一定相同)。客观下线(FAIL):此时 A 发现其他很多节点,也认为 B 为
PFAIL,并且数目超过总集群个数的一半,那么 A 就会把 B 标记成FAIL(相当于客观下线),并且把这个消息同步给其他节点(其他节点收到之后,也会把 B 标记成FAIL)。
流程时序图 (Mermaid)
sequenceDiagram
participant A as 节点A
participant B as 节点B
participant C as 节点C
participant D as 节点D
Note over A, D: 1. 常规随机心跳检测
loop 每秒钟的随机PING
A->>B: PING (携带集群信息)
B-->>A: PONG
end
Note over A, B: 2. 节点B无响应
A->>B: PING
Note right of B: 节点B故障/无响应
A->>B: 尝试重置TCP连接
Note right of B: 连接失败
Note over A: 3. 节点A将节点B标记为 PFAIL (主观下线)
Note over A, D: 4. 通过Gossip协议传播并确认状态
A->>C: PING (消息体中包含:B is PFAIL)
A->>D: PING (消息体中包含:B is PFAIL)
C-->>A: PONG (消息体中包含:我也认为B is PFAIL)
D-->>A: PONG (消息体中包含:我也认为B is PFAIL)
Note over A: 5. 统计PFAIL投票
Note right of A: 认为B下线的节点数 > 集群半数
Note over A: 6. 节点A将节点B标记为 FAIL (客观下线)
Note over A, D: 7. 广播FAIL消息,达成集群共识
A->>C: 将B标记为FAIL
A->>D: 将B标记为FAIL
- 随机心跳:展示了初始的正常通信状态。
- 故障开始:节点 B 停止响应
PING,并且 TCP 重连失败,触发了主观下线(PFAIL)。- Gossip 传播:节点 A 将 B 的 PFAIL 状态通过后续的
PING消息(作为 Gossip 协议的一部分)告知其他节点,并收集它们的看法。- 投票与裁决:节点 A 收集到足够多(超过半数)的相同观点后,将 B 的状态升级为客观下线(FAIL)。
- 集群广播:节点 A 将 FAIL 决定广播出去,使集群状态最终一致,为后续的故障转移(Failover)做好准备。
至此,B 节点就被正式标记为 FAIL 状态了,接下来就可以进行故障转移(Failover)了。
故障转移(Failover)
前提条件
上述例子中,主节点 B 发生故障,并且已被集群客观下线(标记为 FAIL)。此时,由 B 的从节点(例如 C 和 D)触发故障迁移流程,旨在选举出一个新的主节点。
故障迁移流程
资格检查:从节点(C 和 D)判定自己是否具有参选资格。如果从节点和主节点断开通信的时间超过阈值(认为从节点的数据和主节点差异过大),就失去竞选资格。
延迟竞选:具有资格的节点会先进入一段休眠时间,其计算公式为:
休眠时间 = 500ms 基础时间 + [0, 500ms] 随机时间 + 排名 * 1000ms- 排名由复制偏移量(offset)决定,
offset越大(数据越新)的从节点排名越靠前(排名值越小),因此其休眠时间更短。
- 排名由复制偏移量(offset)决定,
发起拉票:假设节点 C 的休眠时间先到,C 就会向集群中的所有主节点发起投票请求(从节点没有投票权)。
投票与晋升:
- 每个主节点只有一票,它会将票投给最先且有效的请求者。
- 当 C 收到的票数超过集群主节点数目的一半时,选举成功。
- C 会将自己晋升为主节点(执行
slaveof no one),并命令其他从节点(如 D)复制自己(让 D 执行slaveof C)。
更新集群状态:C 会将自己成为新主节点的消息通过 Gossip 协议广播给集群中的所有其他节点。所有节点都会更新本地存储的集群配置信息,指向新的拓扑结构。
注:上述选举过程的核心思想来源于 Raft 算法。在随机休眠时间的机制下,数据最同步(offset 最大)的从节点通常会最先唤醒并赢得选举。
故障迁移时序图 (Mermaid)
sequenceDiagram
participant A as 主节点A
participant B as 主节点B(FAIL)
participant C as 从节点C(B的副本)
participant D as 从节点D(B的副本)
participant E as 其他主节点
Note over C, D: 1. 资格检查
Note right of C: 数据同步良好,有资格
Note right of D: 数据同步良好,有资格
Note over C, D: 2. 计算休眠时间
Note right of C: Offset较大,排名靠前
休眠时间较短
Note right of D: Offset较小,排名靠后
休眠时间较长
Note over C: 3. C的休眠时间先到
C->>A: 请求投票
C->>E: 请求投票(广播给所有主节点)
Note over A, E: 4. 投票
A-->>C: 投票给C
E-->>C: 投票给C
Note right of C: 收集到超过半数的票
Note over C: 5. 选举成功,自我晋升
C->>C: slaveof no one
C->>D: SLAVEOF (命令D复制自己)
Note over C: 6. 广播新配置
C->>A: 通知B:FAIL, 新主为C
C->>E: 通知B:FAIL, 新主为C
C->>D: 通知B:FAIL, 新主为C
Note over All: 集群状态达成一致
Note over C: 新任主节点
Note over D: 成为C的从节点
图中的关键点说明
- 资格与延迟:展示了从节点根据自身数据新旧程度(排名)获得不同的竞选优势(休眠时间长短)。
- 拉票与投票:展示了最先醒来的从节点 C 向所有主节点广播投票请求,并收集选票的过程。
- 晋升与接管:展示了节点 C 在获得足够票数后,执行两个关键操作:1) 解除自身从节点状态;2) 接管其他旧主的从节点。
- 信息同步:最后,新主节点 C 将集群结构变更的消息广播出去,使整个集群达成共识,完成故障迁移。
集群扩容测试
扩容在开发环境中非常常见,尤其是在业务量增长时。Redis 集群支持在线扩容,可以动态添加新的节点而不影响现有集群的运行。而在生产环境中,扩容通常需要更谨慎的操作,可能涉及数据迁移和重新分配哈希槽。
第一步:把新的主节点加入到集群
上面我们已经把 redis1 - redis9 这 9 个节点加入到了集群中,现在我们再将节点 redis10 和 redis11 加入到集群中去:
此处我们把 redis10 作为主机,而 redis11 作为它的从节点。
root@92ba490d5c8d:/data# redis-cli --cluster add-node 172.30.0.110:6379 172.30.0.101:6379
>>> Adding node 172.30.0.110:6379 to cluster 172.30.0.101:6379
>>> Performing Cluster Check (using node 172.30.0.101:6379)
M: ccaf61741c1209b3bb746480b84a0ea0c8cbb87c 172.30.0.101:6379
slots:[0-5460] (5461 slots) master
2 additional replica(s)
S: 23b2ee4aa3170eec669af17284982b6da13e48d2 172.30.0.107:6379
slots: (0 slots) slave
replicates 3ba092a8b1547bcf2772b7da2b96f70805923f0f
S: 510e72ddb6afdb74f4a89d7eb021f8e80897c95e 172.30.0.105:6379
slots: (0 slots) slave
replicates ccaf61741c1209b3bb746480b84a0ea0c8cbb87c
S: 61c77b70e815c201e56bbfc25c68cd6cbe367b8b 172.30.0.104:6379
slots: (0 slots) slave
replicates 11f517397c7b986450d5ae213d0e19767944dc11
S: 33de5344df9b7d89141d24292e91ec33d754a039 172.30.0.109:6379
slots: (0 slots) slave
replicates 11f517397c7b986450d5ae213d0e19767944dc11
M: 3ba092a8b1547bcf2772b7da2b96f70805923f0f 172.30.0.102:6379
slots:[5461-10922] (5462 slots) master
2 additional replica(s)
S: f3734a1c3bc5520977ea9ace9c8894dd55b6efd4 172.30.0.106:6379
slots: (0 slots) slave
replicates ccaf61741c1209b3bb746480b84a0ea0c8cbb87c
M: 11f517397c7b986450d5ae213d0e19767944dc11 172.30.0.103:6379
slots:[10923-16383] (5461 slots) master
2 additional replica(s)
S: 69fd461e80f8b2bc7d4c2856eb20039aed56b824 172.30.0.108:6379
slots: (0 slots) slave
replicates 3ba092a8b1547bcf2772b7da2b96f70805923f0f
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Getting functions from cluster
>>> Send FUNCTION LIST to 172.30.0.110:6379 to verify there is no functions in it
>>> Send FUNCTION RESTORE to 172.30.0.110:6379
>>> Send CLUSTER MEET to node 172.30.0.110:6379 to make it join the cluster.
[OK] New node added correctly.要想将新的节点加入到集群中,我们得指定一个被加入的集群中的任意节点的 IP 地址和端口号(这里我指定的是 172.30.0.101:6379)。
172.30.0.101:6379> cluster nodes
ccaf61741c1209b3bb746480b84a0ea0c8cbb87c 172.30.0.101:6379@16379 myself,master - 0 0 11 connected 0-5460
23b2ee4aa3170eec669af17284982b6da13e48d2 172.30.0.107:6379@16379 slave 3ba092a8b1547bcf2772b7da2b96f70805923f0f 0 1758427054045 2 connected
510e72ddb6afdb74f4a89d7eb021f8e80897c95e 172.30.0.105:6379@16379 slave ccaf61741c1209b3bb746480b84a0ea0c8cbb87c 0 1758427054549 11 connected
61c77b70e815c201e56bbfc25c68cd6cbe367b8b 172.30.0.104:6379@16379 slave 11f517397c7b986450d5ae213d0e19767944dc11 0 1758427053542 3 connected
33de5344df9b7d89141d24292e91ec33d754a039 172.30.0.109:6379@16379 slave 11f517397c7b986450d5ae213d0e19767944dc11 0 1758427053039 3 connected
c1625fb8d5441e9dd6fef7b60c5944c5519dfaa9 172.30.0.110:6379@16379 master - 0 1758427054246 0 connected
3ba092a8b1547bcf2772b7da2b96f70805923f0f 172.30.0.102:6379@16379 master - 0 1758427053039 2 connected 5461-10922
f3734a1c3bc5520977ea9ace9c8894dd55b6efd4 172.30.0.106:6379@16379 slave ccaf61741c1209b3bb746480b84a0ea0c8cbb87c 0 1758427053240 11 connected
11f517397c7b986450d5ae213d0e19767944dc11 172.30.0.103:6379@16379 master - 0 1758427054549 3 connected 10923-16383
69fd461e80f8b2bc7d4c2856eb20039aed56b824 172.30.0.108:6379@16379 slave 3ba092a8b1547bcf2772b7da2b96f70805923f0f 0 1758427053000 2 connected可以看到,新加入的节点默认是主节点,但是没有分配任何哈希槽,因此下一步,我们需要手动给它分配哈希槽。
第二步:给新节点分配哈希槽
我们可以使用 redis-cli --cluster reshard 命令来给新节点分配哈希槽:
root@92ba490d5c8d:/data# redis-cli --cluster reshard 172.30.0.101:6379
>>> Performing Cluster Check (using node 172.30.0.101:6379)
M: ccaf61741c1209b3bb746480b84a0ea0c8cbb87c 172.30.0.101:6379
slots:[0-5460] (5461 slots) master
2 additional replica(s)
S: 23b2ee4aa3170eec669af17284982b6da13e48d2 172.30.0.107:6379
slots: (0 slots) slave
replicates 3ba092a8b1547bcf2772b7da2b96f70805923f0f
S: 510e72ddb6afdb74f4a89d7eb021f8e80897c95e 172.30.0.105:6379
slots: (0 slots) slave
replicates ccaf61741c1209b3bb746480b84a0ea0c8cbb87c
S: 61c77b70e815c201e56bbfc25c68cd6cbe367b8b 172.30.0.104:6379
slots: (0 slots) slave
replicates 11f517397c7b986450d5ae213d0e19767944dc11
S: 33de5344df9b7d89141d24292e91ec33d754a039 172.30.0.109:6379
slots: (0 slots) slave
replicates 11f517397c7b986450d5ae213d0e19767944dc11
M: c1625fb8d5441e9dd6fef7b60c5944c5519dfaa9 172.30.0.110:6379
slots: (0 slots) master
M: 3ba092a8b1547bcf2772b7da2b96f70805923f0f 172.30.0.102:6379
slots:[5461-10922] (5462 slots) master
2 additional replica(s)
S: f3734a1c3bc5520977ea9ace9c8894dd55b6efd4 172.30.0.106:6379
slots: (0 slots) slave
replicates ccaf61741c1209b3bb746480b84a0ea0c8cbb87c
M: 11f517397c7b986450d5ae213d0e19767944dc11 172.30.0.103:6379
slots:[10923-16383] (5461 slots) master
2 additional replica(s)
S: 69fd461e80f8b2bc7d4c2856eb20039aed56b824 172.30.0.108:6379
slots: (0 slots) slave
replicates 3ba092a8b1547bcf2772b7da2b96f70805923f0f
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 4096
What is the receiving node ID? c1625fb8d5441e9dd6fef7b60c5944c5519dfaa9
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: all
......迁移过程中它会现将他的计划迁移的哈希槽数、目标节点 ID 和源节点 ID 让我们确认一遍,确认无误后,它会开始迁移哈希槽(这可是给你踩刹车的好机会,过了这个村就没这个店了),如果操作不好,这在生产环境中可是会引起严重后果的。
172.30.0.101:6379> cluster nodes
ccaf61741c1209b3bb746480b84a0ea0c8cbb87c 172.30.0.101:6379@16379 myself,master - 0 0 11 connected 1365-5460
23b2ee4aa3170eec669af17284982b6da13e48d2 172.30.0.107:6379@16379 slave c1625fb8d5441e9dd6fef7b60c5944c5519dfaa9 0 1758428052652 12 connected
510e72ddb6afdb74f4a89d7eb021f8e80897c95e 172.30.0.105:6379@16379 slave ccaf61741c1209b3bb746480b84a0ea0c8cbb87c 0 1758428052000 11 connected
61c77b70e815c201e56bbfc25c68cd6cbe367b8b 172.30.0.104:6379@16379 slave 11f517397c7b986450d5ae213d0e19767944dc11 0 1758428051000 3 connected
33de5344df9b7d89141d24292e91ec33d754a039 172.30.0.109:6379@16379 slave 11f517397c7b986450d5ae213d0e19767944dc11 0 1758428052000 3 connected
c1625fb8d5441e9dd6fef7b60c5944c5519dfaa9 172.30.0.110:6379@16379 master - 0 1758428051000 12 connected 0-1364 5461-6826 10923-12287
3ba092a8b1547bcf2772b7da2b96f70805923f0f 172.30.0.102:6379@16379 master - 0 1758428051000 2 connected 6827-10922
f3734a1c3bc5520977ea9ace9c8894dd55b6efd4 172.30.0.106:6379@16379 slave ccaf61741c1209b3bb746480b84a0ea0c8cbb87c 0 1758428051000 11 connected
11f517397c7b986450d5ae213d0e19767944dc11 172.30.0.103:6379@16379 master - 0 1758428051646 3 connected 12288-16383
69fd461e80f8b2bc7d4c2856eb20039aed56b824 172.30.0.108:6379@16379 slave 3ba092a8b1547bcf2772b7da2b96f70805923f0f 0 1758428052551 2 connected可以看到,redis10 节点已经被分配了部分哈希槽,分别来自 redis1、redis3 和 redis2 三个节点。
第三步:给新的主节点添加从节点
为了保证集群的高可用性,我们还需要给新的主节点 redis10 添加一个从节点 redis11:
root@92ba490d5c8d:/data# redis-cli --cluster add-node 172.30.0.111:6379 172.30.0.101:6379 --cluster-slave --cluster-master-id c1625fb8d5441e9dd6fef7b60c5944c5519dfaa9
>>> Adding node 172.30.0.111:6379 to cluster 172.30.0.101:6379
>>> Performing Cluster Check (using node 172.30.0.101:6379)
M: ccaf61741c1209b3bb746480b84a0ea0c8cbb87c 172.30.0.101:6379
slots:[1365-5460] (4096 slots) master
2 additional replica(s)
S: 23b2ee4aa3170eec669af17284982b6da13e48d2 172.30.0.107:6379
slots: (0 slots) slave
replicates c1625fb8d5441e9dd6fef7b60c5944c5519dfaa9
S: 510e72ddb6afdb74f4a89d7eb021f8e80897c95e 172.30.0.105:6379
slots: (0 slots) slave
replicates ccaf61741c1209b3bb746480b84a0ea0c8cbb87c
S: 61c77b70e815c201e56bbfc25c68cd6cbe367b8b 172.30.0.104:6379
slots: (0 slots) slave
replicates 11f517397c7b986450d5ae213d0e19767944dc11
S: 33de5344df9b7d89141d24292e91ec33d754a039 172.30.0.109:6379
slots: (0 slots) slave
replicates 11f517397c7b986450d5ae213d0e19767944dc11
M: c1625fb8d5441e9dd6fef7b60c5944c5519dfaa9 172.30.0.110:6379
slots:[0-1364],[5461-6826],[10923-12287] (4096 slots) master
1 additional replica(s)
M: 3ba092a8b1547bcf2772b7da2b96f70805923f0f 172.30.0.102:6379
slots:[6827-10922] (4096 slots) master
1 additional replica(s)
S: f3734a1c3bc5520977ea9ace9c8894dd55b6efd4 172.30.0.106:6379
slots: (0 slots) slave
replicates ccaf61741c1209b3bb746480b84a0ea0c8cbb87c
M: 11f517397c7b986450d5ae213d0e19767944dc11 172.30.0.103:6379
slots:[12288-16383] (4096 slots) master
2 additional replica(s)
S: 69fd461e80f8b2bc7d4c2856eb20039aed56b824 172.30.0.108:6379
slots: (0 slots) slave
replicates 3ba092a8b1547bcf2772b7da2b96f70805923f0f
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 172.30.0.111:6379 to make it join the cluster.
Waiting for the cluster to join
>>> Configure node as replica of 172.30.0.110:6379.
[OK] New node added correctly.后面填写的 ID 参数是 redis10 的节点 ID。
执行完毕后,从节点就已经被添加完成了,至此实验结束。