
Linux 线程信号量(POSIX)--优化多生产者-消费者框架
七月 26, 2025
次阅读
POSIX线程信号量(Semaphore)
基本概念
POSIX信号量是一种用于线程同步的机制,主要用于控制对共享资源的访问。它维护一个计数器,提供两种基本操作:
- P操作(wait):计数器减1,如果计数器为0则阻塞
- V操作(post):计数器加1,唤醒等待的线程
核心函数
sem_init() - 初始化信号量
int sem_init(sem_t *sem, int pshared, unsigned int value);sem:信号量指针pshared:0表示线程间共享(进程间使用设为非零)value:信号量初始值
sem_wait() - P操作(获取资源)
int sem_wait(sem_t *sem);- 原子地减少信号量值
- 如果值为0则阻塞,直到信号量变为正数
sem_post() - V操作(释放资源)
int sem_post(sem_t *sem);- 原子地增加信号量值
- 如果有线程在等待,唤醒其中一个
sem_destroy() - 销毁信号量
int sem_destroy(sem_t *sem);典型使用场景
#include <semaphore.h>
sem_t sem; // 声明信号量
// 初始化信号量(初始值为1)
sem_init(&sem, 0, 1);
// 线程1
void* thread_func1(void* arg) {
sem_wait(&sem); // P操作
// 临界区代码
sem_post(&sem); // V操作
return NULL;
}
// 线程2
void* thread_func2(void* arg) {
sem_wait(&sem); // P操作
// 临界区代码
sem_post(&sem); // V操作
return NULL;
}
// 销毁信号量
sem_destroy(&sem);信号量 vs 互斥锁
| 特性 | 信号量 | 互斥锁 |
|---|---|---|
| 初始值 | 可设为任意非负整数 | 通常初始为1(解锁状态) |
| 所有者 | 无所有者概念 | 有所有者(哪个线程锁定) |
| 操作 | post/wait | lock/unlock |
| 主要用途 | 资源计数/同步 | 保护临界区 |
注意事项
- 必须正确初始化信号量
- 避免死锁(特别是多个信号量使用时)
- 信号量没有自动释放机制(不像互斥锁的pthread_mutex_trylock)
- 销毁正在被等待的信号量会导致未定义行为
POSIX信号量为线程同步提供了灵活的计数机制,特别适合需要控制多个线程访问多个资源实例的场景。
下面我们基于 POSIX 线程信号量设计一个环形队列来处理生产者消费者问题:
环形队列采用数组模拟,用模运算来模拟环状特性
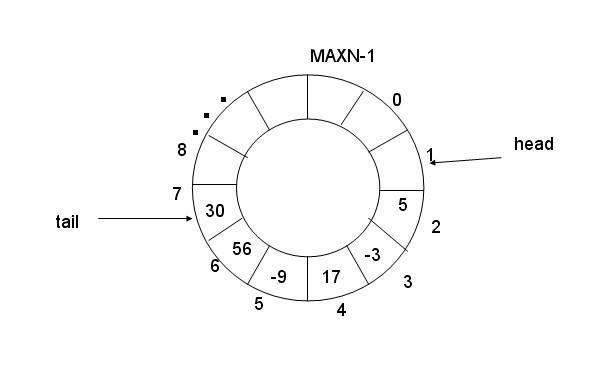
环形结构起始状态和结束状态都是⼀样的,不好判断为空或者为满,所以可以通过加计数器或者标记位来判断满或者空。另外也可以预留⼀个空的位置,作为满的状态
生产者-消费者问题
下面我将详细讲解基于环形队列(RingQueue)实现的生产者-消费者模型,并对代码进行完整注释和分析。
1. 核心组件解析
1.1 LockGuard - RAII锁守卫类
class LockGuard {
public:
explicit LockGuard(pthread_mutex_t &mtx) : mtx_(mtx) {
pthread_mutex_lock(&mtx_); // 构造时自动加锁
}
~LockGuard() {
pthread_mutex_unlock(&mtx_); // 析构时自动解锁
}
// 禁用拷贝构造和赋值操作
LockGuard(const LockGuard&) = delete;
LockGuard& operator=(const LockGuard&) = delete;
private:
pthread_mutex_t &mtx_; // 引用外部互斥锁
};- 采用RAII(资源获取即初始化)技术管理互斥锁
- 构造时自动加锁,析构时自动解锁,避免忘记解锁
- 禁用拷贝构造和赋值,确保锁管理的唯一性
1.2 RingQueue - 环形队列模板类
template<class T>
class RingQueue {
private:
// 封装信号量P操作(等待)
void P(sem_t &sem) { sem_wait(&sem); }
// 封装信号量V操作(释放)
void V(sem_t &sem) { sem_post(&sem); }
public:
// 构造函数
RingQueue(size_t cap = 10)
: cap_(cap), c_index_(0), p_index_(0), queue(cap)
{
pthread_mutex_init(&p_mutex_, nullptr); // 生产者互斥锁
pthread_mutex_init(&c_mutex_, nullptr); // 消费者互斥锁
sem_init(&space_sem_, 0, cap_); // 空间信号量(初始=容量)
sem_init(&data_sem_, 0, 0); // 数据信号量(初始=0)
}
// 析构函数
~RingQueue() {
pthread_mutex_destroy(&p_mutex_);
pthread_mutex_destroy(&c_mutex_);
sem_destroy(&space_sem_);
sem_destroy(&data_sem_);
}
// 生产者接口:添加任务
void Push(const T & task) {
P(space_sem_); // 等待有空闲空间
{
LockGuard lg(p_mutex_); // 加生产者锁
queue[p_index_] = task; // 放入任务
p_index_ = (p_index_ + 1) % cap_; // 更新生产者索引
}
V(data_sem_); // 增加数据信号量
}
// 消费者接口:获取任务
T Pop() {
T task;
P(data_sem_); // 等待有数据
{
LockGuard lg(c_mutex_); // 加消费者锁
task = queue[c_index_]; // 取出任务
c_index_ = (c_index_ + 1) % cap_; // 更新消费者索引
}
V(space_sem_); // 增加空间信号量
return task;
}
private:
sem_t space_sem_; // 空间信号量(剩余可生产空间)
sem_t data_sem_; // 数据信号量(现有可消费数据)
pthread_mutex_t p_mutex_; // 生产者互斥锁
pthread_mutex_t c_mutex_; // 消费者互斥锁
size_t cap_; // 队列容量
size_t c_index_; // 消费者索引
size_t p_index_; // 生产者索引
std::vector<T> queue; // 底层存储容器
};2. 工作原理详解
2.1 同步机制设计
双信号量控制:
space_sem_:表示剩余可生产空间,初始值为队列容量data_sem_:表示现有可消费数据,初始值为0
双互斥锁设计:
p_mutex_:保护生产者端的队列操作c_mutex_:保护消费者端的队列操作- 生产者和消费者使用不同的锁,提高并发性能
2.2 生产者流程(Push)
P(space_sem_):等待有空闲位置(信号量>0)- 获取生产者锁
p_mutex_ - 将任务放入队列
p_index_位置 - 更新生产者索引(环形计算)
- 释放生产者锁
V(data_sem_):增加可消费数据计数
2.3 消费者流程(Pop)
P(data_sem_):等待有可消费数据(信号量>0)- 获取消费者锁
c_mutex_ - 从队列
c_index_位置取出任务 - 更新消费者索引(环形计算)
- 释放消费者锁
V(space_sem_):增加可用空间计数
3. 环形队列特性
索引计算:
p_index_ = (p_index_ + 1) % cap_; // 生产者索引更新 c_index_ = (c_index_ + 1) % cap_; // 消费者索引更新- 通过取模运算实现环形缓冲区
- 当索引到达末尾时自动回到开头
读写分离:
- 生产者和消费者使用不同的索引
- 读写操作不会互相干扰
4. 性能优化点
锁分离:
- 生产者和消费者使用不同的互斥锁
- 减少锁竞争,提高并发性能
RAII锁管理:
- 使用LockGuard自动管理锁的生命周期
- 避免忘记解锁导致的死锁
信号量先行:
- 先检查信号量再获取锁
- 减少持有锁时的等待时间
我们来测试一下修改后的模型和原先基于阻塞队列的模型相比哪一个更快一些:
基于阻塞队列的模型测试用例:
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <vector>
#include <chrono>
#include <semaphore.h>
#include "Task.hpp"
#include "block_queue.hpp"
#include "ring_queue.hpp"
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
using namespace std;
const int consumer_num = 20;
const int producer_num = 20;
const int total_task = 100000;
sem_t sem_cons;
sem_t sem_pro;
char opers[] = {'+', '-', '*', '/', '%'};
struct thread_data{
string name;
BlockQueue<Task> *bq;
sem_t sem;
};
class Timer
{
private:
std::chrono::time_point<std::chrono::high_resolution_clock> start_time;
public:
Timer()
{
start();
}
void start()
{
start_time = std::chrono::high_resolution_clock::now();
}
~Timer()
{
std::cout << elapsed() << endl;
}
// 返回经过的毫秒数
double elapsed() const
{
auto end_time = std::chrono::high_resolution_clock::now();
return std::chrono::duration<double, std::milli>(end_time - start_time).count();
}
// 返回经过的秒数
double elapsedSeconds() const
{
return elapsed() / 1000.0;
}
};
void *Producer(void *args)
{
thread_data *td = static_cast<thread_data *>(args);
string name = td->name;
BlockQueue<Task> *bq = td->bq;
while(true)
{
if(sem_trywait(&sem_pro)) break;
usleep(10);
int num1 = rand() % 10;
int num2 = rand() % 10;
char op = opers[rand() % 5];
Task task{num1, num2, op};
// pthread_mutex_lock(&mutex);
// cout << name << ": " << task.GetTask() << endl;
// pthread_mutex_unlock(&mutex);
bq->Push(task);
}
return nullptr;
}
void *Consumer(void *args)
{
thread_data *td = static_cast<thread_data *>(args);
string name = td->name;
BlockQueue<Task> *bq = td->bq;
while(true)
{
if(sem_trywait(&sem_cons)) break;
usleep(10);
Task task = bq->Pop();
task();
// pthread_mutex_lock(&mutex);
// cout << name << ": " << task.GetResult() << endl;
// pthread_mutex_unlock(&mutex);
}
return nullptr;
}
int main()
{
srand(time(nullptr));
BlockQueue<Task> bq(30);
RingQueue<Task> rq(30);
vector<pthread_t> tids;
sem_init(&sem_cons, 0, total_task);
sem_init(&sem_pro, 0, total_task);
for(int i = 1; i <= producer_num; ++i)
{
string name = "producer-" + to_string(i);
thread_data *td = new thread_data{
name: name,
bq: &bq
};
pthread_t tid;
pthread_create(&tid, nullptr, Producer, (void*)(td));
tids.push_back(tid);
}
for(int i = 1; i <= consumer_num; ++i)
{
string name = "consumer-" + to_string(i);
thread_data *td = new thread_data{
name: name,
bq: &bq
};
pthread_t tid;
pthread_create(&tid, nullptr, Consumer, (void*)(td));
tids.push_back(tid);
}
{
Timer time;
for(auto tid: tids) pthread_join(tid, nullptr);
}
return 0;
}测试结果:
# 第一次
╭─ljx@VM-16-15-debian ~/linux_review/thread
╰─➤ ./cp.o
755.378
# 第二次
╭─ljx@VM-16-15-debian ~/linux_review/thread
╰─➤ ./cp.o
935.271
# 第三次
╭─ljx@VM-16-15-debian ~/linux_review/thread
╰─➤ ./cp.o
1158.35
# 第四次
╭─ljx@VM-16-15-debian ~/linux_review/thread
╰─➤ ./cp.o
925.125
# 第五次
╭─ljx@VM-16-15-debian ~/linux_review/thread
╰─➤ ./cp.o
1100.93平均用时:755.378 + 935.271 + 1158.35 + 925.125 + 1100.93 = 5870.05 / 5 = 1174.01
基于环形队列的模型测试用例:
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <vector>
#include <chrono>
#include <semaphore.h>
#include "Task.hpp"
#include "block_queue.hpp"
#include "ring_queue.hpp"
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
using namespace std;
const int consumer_num = 20;
const int producer_num = 20;
const int total_task = 100000;
sem_t sem_cons;
sem_t sem_pro;
char opers[] = {'+', '-', '*', '/', '%'};
struct thread_data{
string name;
RingQueue<Task> *rq;
sem_t sem;
};
class Timer
{
private:
std::chrono::time_point<std::chrono::high_resolution_clock> start_time;
public:
Timer()
{
start();
}
void start()
{
start_time = std::chrono::high_resolution_clock::now();
}
~Timer()
{
std::cout << elapsed() << endl;
}
// 返回经过的毫秒数
double elapsed() const
{
auto end_time = std::chrono::high_resolution_clock::now();
return std::chrono::duration<double, std::milli>(end_time - start_time).count();
}
// 返回经过的秒数
double elapsedSeconds() const
{
return elapsed() / 1000.0;
}
};
void *Producer(void *args)
{
thread_data *td = static_cast<thread_data *>(args);
string name = td->name;
RingQueue<Task> *rq = td->rq;
while(true)
{
if(sem_trywait(&sem_pro)) break;
usleep(10);
int num1 = rand() % 10;
int num2 = rand() % 10;
char op = opers[rand() % 5];
Task task{num1, num2, op};
// pthread_mutex_lock(&mutex);
// cout << name << ": " << task.GetTask() << endl;
// pthread_mutex_unlock(&mutex);
rq->Push(task);
}
return nullptr;
}
void *Consumer(void *args)
{
thread_data *td = static_cast<thread_data *>(args);
string name = td->name;
RingQueue<Task> *rq = td->rq;
while(true)
{
if(sem_trywait(&sem_cons)) break;
usleep(10);
Task task = rq->Pop();
task();
// pthread_mutex_lock(&mutex);
// cout << name << ": " << task.GetResult() << endl;
// pthread_mutex_unlock(&mutex);
}
return nullptr;
}
int main()
{
srand(time(nullptr));
BlockQueue<Task> bq(30);
RingQueue<Task> rq(30);
vector<pthread_t> tids;
sem_init(&sem_cons, 0, total_task);
sem_init(&sem_pro, 0, total_task);
for(int i = 1; i <= consumer_num; ++i)
{
string name = "producer-" + to_string(i);
thread_data *td = new thread_data{
name: name,
rq: &rq
};
pthread_t tid;
pthread_create(&tid, nullptr, Producer, (void*)(td));
tids.push_back(tid);
}
for(int i = 1; i <= producer_num; ++i)
{
string name = "consumer-" + to_string(i);
thread_data *td = new thread_data{
name: name,
rq: &rq
};
pthread_t tid;
pthread_create(&tid, nullptr, Consumer, (void*)(td));
tids.push_back(tid);
}
{
Timer time;
for(auto tid: tids) pthread_join(tid, nullptr);
}
return 0;
}测试结果:
# 第一次
╭─ljx@VM-16-15-debian ~/linux_review/thread
╰─➤ ./cp.o
685.519
# 第二次
╭─ljx@VM-16-15-debian ~/linux_review/thread
╰─➤ ./cp.o
688.496
# 第三次
╭─ljx@VM-16-15-debian ~/linux_review/thread
╰─➤ ./cp.o
655.452
# 第四次
╭─ljx@VM-16-15-debian ~/linux_review/thread
╰─➤ ./cp.o
684.919
# 第五次
╭─ljx@VM-16-15-debian ~/linux_review/thread
╰─➤ ./cp.o
665.94平均用时:685.519 + 688.496 + 655.452 + 684.919 + 665.94 = 3380.326 / 5 = 676.0652
由此可见,在多生产者多消费者场景下,基于信号量的环形队列(RingQueue)通常比传统阻塞队列(BlockingQueue)有更好的性能表现,具体比较如下:
- 锁粒度差异
| 队列类型 | 锁机制 | 并发度影响 |
|---|---|---|
| 传统阻塞队列 | 全局单一互斥锁 | 所有操作串行化,竞争激烈 |
| 环形队列 | 生产者/消费者双锁分离 | 生产消费可并行 |
- 系统调用开销
| 操作 | 阻塞队列 | 环形队列 |
|---|---|---|
| 入队/出队 | 可能触发线程调度 | 纯用户态操作(信号量) |
| 临界区执行时间 | 较长(含动态内存分配) | 极短(仅索引计算) |
因此,在大多数的多生产者多消费者场景下,更推荐使用基于信号量的环形队列模型。
查看评论