
Linux 进程概念
进程基本概念理解
进程(Process)是计算机中正在运行的程序实例,是操作系统进行资源分配和调度的基本单位。每个进程都有独立的内存空间、代码、数据和系统资源(如文件句柄、网络连接等)
不要把进程理解成一个非常高深的概念,进程还有另一个你可能听得更多的名称,叫做任务,在 Windows 中,你启动一个软件本质上就是创建了一个进程,这个进程是被操作系统管理起来的
而一个操作系统需要管理的进程数量肯定不止这一个。例如,在操作系统启动的时候,就会有许多系统级进程(守护进程等等)自动创建出来,因此,管理一个个进程的过程可以被理解成一个
学校管理学生的过程
一个进程通常包含:
- 代码段(Text Segment)
- 存储程序的可执行指令(机器码)。
- 数据段(Data Segment)
- 存储全局变量和静态变量。
- 堆(Heap)
- 动态分配的内存(如
malloc()或new申请的空间)。
- 动态分配的内存(如
- 栈(Stack)
- 存储局部变量、函数调用信息(如返回地址、参数)。
- 进程控制块(PCB)
- 操作系统维护的元数据,包括:
- 进程 ID(PID)
- 进程状态(运行、就绪、阻塞等)
- 寄存器值(程序计数器、堆栈指针等)
- 资源占用情况(打开的文件、内存分配等)
- 操作系统维护的元数据,包括:
乍一看感觉进程有好多好多的东西,但你再仔细观察一下,1到4都可以被统称为进程运行所需要的基本数据,在编写一个程序的时候,你需要编写一段代码并将它编译后
形成可执行程序,这个可执行程序是一段二进制代码,这段二进制代码会被计算机(如冯诺依曼架构)执行,通过指令寄存器一一读取,再被控制单元(CU)译码转化为实际的行为,
而数据段就是运行代码时需要通过寻址找到的数据,这些数据被存储在了内存当中,而他也是一个进程的一部分。堆和栈一个用于动态分配内存并使用,另一个用于存储局部变量以及函数
的调用,这些都是一个程序要运行起来所必须的部分。
回到学校管理学生的例子,程序的 代码段、数据段、堆、栈 就好比学生自己本身,他是进程运行所需要的自身因素,而进程控
制块内部存储的进程 ID 就好比学校管理学生给学生编的一个唯一标识–学号,进程状态就好比
学校判断学生是在读,还是在休假,而资源占用情况可以理解为学校判断一个学生的考核情况,违纪情况以及奖赏情况
没错,学校对大量的学生进行管理,操作系统对大量进程的管理同样也叫做管理,管理这个词不仅仅是用于实际生活中的,操作系统中对进程既然是做了管理,那么就得用同样的一套思路去管理他们
因此,我们将进程分为两部分,代码和数据是一部分,而进程控制块(PCB)是另一部分,进程本身运作起来依赖于代码和数据,而何时运作,运作方式如何,该不该运作等等就由进程控制块去控制,
这就好比你在学校里面该如何活动是有你自身来决定的,但你该干什么,何时去做某件事就是由学校来控制你了,学校控制你的方式可以是给你一个课程表,给你安排一场考试等等
进程的特点如下(不需要特别去理解,后面讲解过程中会逐一理解它们的):
| 特征 | 说明 |
|---|---|
| 动态性 | 进程是程序的一次执行过程,有创建、运行、暂停、终止的生命周期。 |
| 独立性 | 每个进程拥有独立的地址空间,一个进程崩溃不会直接影响其他进程。 |
| 并发性 | 多个进程可以同时运行(通过 CPU 时间片轮转或并行执行)。 |
| 资源拥有者 | 进程是操作系统分配资源(CPU、内存、I/O 设备等)的基本单位。 |
| 结构化信息 | 每个进程由 PCB(Process Control Block) 描述,包含状态、优先级等元数据。 |
上面所讲的进程的概念适用于所有的操作系统,而不仅仅是 Linux,不论是什么操作系统,进程运行一定需要代码和数据,以何种方式运行就依靠于进程控制块(PCB),
因此,操作系统管理每个进程实际上是对进程控制块内部数据的修改,而进程控制块在操作系统中本质上是一个结构体,操作系统管理的进程有很多很多,这就意味着操作系统
需要对很多很多个进程控制结构体进行管理,那就需要将这些结构体通过链表的方式关联起来,因此,再说的通俗一些,操作系统对进程的管理实质上是对一个个由PCB结构体串起来的双链表的增删查改!
而在 Linux 当中,进程控制块有一个属于自己的名字叫做task_struct!!!因此 Linux 对进程的管理实质上是对list
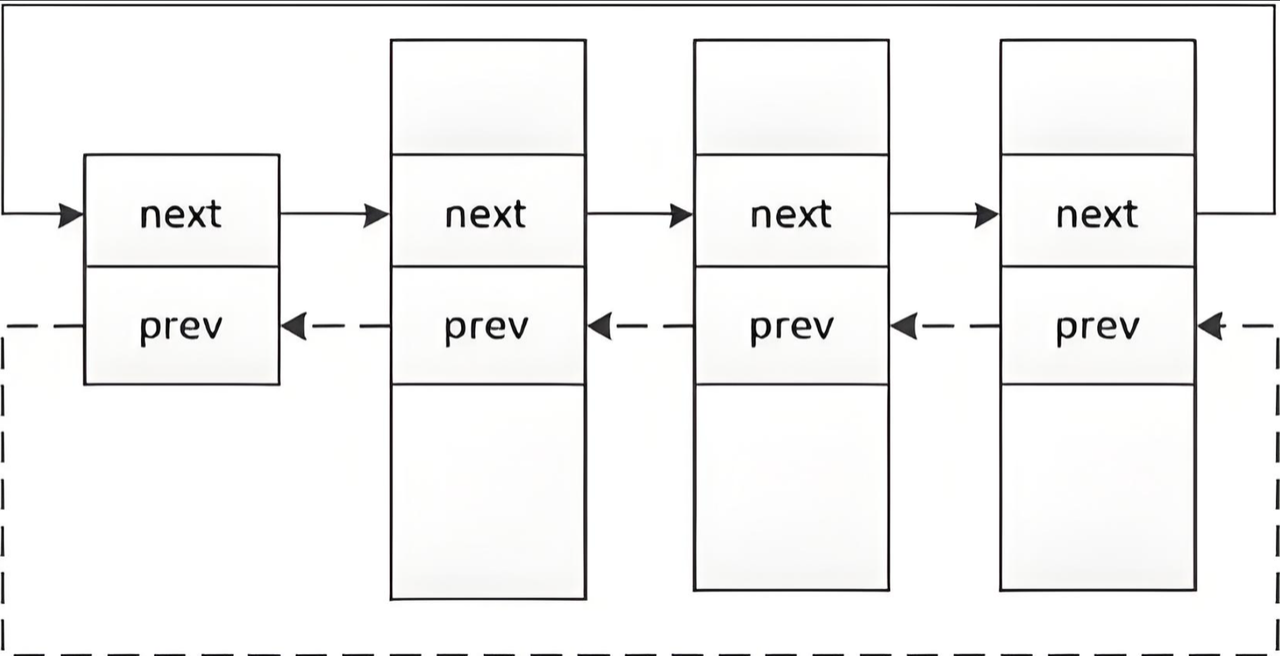
接下来,我们就一起来讨论一下 Linux 的这个进程控制块
Linux 的进程控制块——task_struct
task_struct 是可以用来管理一个进程的所有信息的,因此它内部的数据肯定是相当庞大的,下面是对task_struct内部数据的大致概括:
task_struct 内部结构
- 标示符: 描述本进程的唯一标示符,用来区别其他进程。
- 状态: 任务状态,退出代码,退出信号等。
- 优先级: 相对于其他进程的优先级。
- 程序计数器(PC): 程序中即将被执行的下一条指令的地址。
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。
- 上下文数据: 进程执行时处理器的寄存器中的数据。
- I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
- 记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
- 其他信息
下面我将针对 task_struct 结构体中的每个属性进行说明
标识符 PID
进程标识符是用来区分每一个进程的唯一标识,成为PID(Process ID),首先,我们要学会查看进程的 PID,下面是查看进程 PID 的一个实用命令:
ps axj其中,axj代表的是ps命令的三个选项,选项代表的意义如下:
在Linux中,ps axj 是一个组合了多个选项的命令,用于显示进程信息。各选项的含义如下:
a- 显示所有用户的进程(包括其他用户的进程),而不仅是当前终端的进程。
x- 显示无控制终端的进程(如后台服务、守护进程等)。通常与
a一起使用,以查看所有进程。
- 显示无控制终端的进程(如后台服务、守护进程等)。通常与
j- 以**作业格式(Job format)**显示信息,包括额外的列:
PPID:父进程ID。PGID:进程组ID。SID:会话ID。- 其他与作业控制相关的字段(如
TPGID等)。
- 以**作业格式(Job format)**显示信息,包括额外的列:
下面,我们在 /linux_review/lesson1/dir 下面启动一个可执行程序,并让该可执行程序死循环,然后我们可以通过
该命令查看进程对应信息
╭─ljx@VM-16-15-debian ~/linux_review/lesson1/dir
╰─➤ ps axj | head -1 && ps axj | grep test1
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
1674011 1757149 1757149 1673035 pts/0 1757149 R+ 1003 0:40 ./test1.o
1755563 1757366 1757365 1755563 pts/1 1757365 R+ 1003 0:00 grep --color=auto --exclude-dir=.bzr --exclude-dir=CVS --exclude-dir=.git --exclude-dir=.hg --exclude-dir=.svn --exclude-dir=.idea --exclude-dir=.tox --exclude-dir=.venv --exclude-dir=venv test1- 关键列信息:
PPID:父进程ID。PID:进程ID。PGID:进程组ID。SID:会话ID。TTY:关联的终端(?表示无终端)。STAT:进程状态(如S=休眠,R=运行等)。COMMAND:进程名称或命令行。
其中下面那个 command 为 grep 的是因为我们使用了 grep 命令过滤对应的进程名,而 grep 命令在执行的时候后面带上了我们所要查找的进程名的名称,因此该指令也会被过滤出来
可以看到有一个叫做 PID 的列,表示的是进程的 PID,可以观察到该进程的 PID 为1757149,除了这种观察进程 PID 的方式除外,我们还可以通过查看 /proc 目录下的信息来
查看进程对应数据信息,proc 目录是用来管理进程信息的,通过 “ll /proc” 指令我们可以观察到有一个目录显示的详细信息如下:
dr-xr-xr-x 9 ljx ljx 0 Jul 13 22:03 1757149这个文件的所有者和用户组都是 ljx ,没错,这个就是我的那个正在运行的进程!我们再进去看一下,会发现里面也有很多的文件,其中有一个我们需要重点关注的是:
lrwxrwxrwx 1 ljx ljx 0 Jul 13 22:03 cwd -> /home/ljx/linux_review/lesson1/dir可以看到,cwd -> /home/ljx/linux_review/lesson1/dir,cwd 表示的是进程的当前工作目录(current working directory),而其指向的目录名称为 /home/ljx/linux_review/lesson1/
dir,这不正是我们当前进程所运行的环境吗,所以说为什么我们通过 mkdir 命令创建文件的时候就一定知道是在当前路径下面创建的文件?本质上是因为 mkdir 命令运行起来也是一个进程,
而该进程运行后对应的进程文件目录下有一个 cwd 用于存储当前工作目录信息,这样 mkdir 指令就知道该在哪里创建目录了
下面将讲到 Linux 中进程获取自身 pid 和父进程 pid 的接口函数:
- getpid(),返回值是该进程自己的 pid,
- getppid(),返回值是该进程的父进程的 pid
我们来测试一下这两个接口:
代码如下:
#include <iostream>
#include <unistd.h>
using namespace std;
int main()
{
while(1) {
cout << "my pid is " << getpid() << endl;
cout << "my ppid is " << getppid() << endl;
sleep(1);
}
return 0;
}测试后输出如下:
╭─ljx@VM-16-15-debian ~/linux_review/lesson1/dir
╰─➤ ./test1.o
my pid is 1763828
my ppid is 1674011让我们在测试一次:
╭─ljx@VM-16-15-debian ~/linux_review/lesson1/dir
╰─➤ ./test1.o
my pid is 1764433
my ppid is 1674011然后你会惊奇地发现,两次运行的子进程号确实会变化,这就好比一个学生上了大学后对自己大学不满意,然后复读一年结果又考上了这个大学,
但第二年的学号和上一年肯定是不同了,这里虽然我还没有讲解 ppid 的存在意义,但你可以将父进程理解成管理学生的校长,虽然你小子入了
两次学,但我校长是不变的呀,下面我将讲解一下进程中父进程存在的意义以及为什么这里的父进程不会改变:
在操作系统中,父进程(Parent Process) 的概念是为了实现 进程的层次化管理,主要作用包括:
- 进程创建与继承
- 新进程(子进程)通常由现有进程(父进程)通过
fork()+exec()创建(fork() 指令马上会讲到,exec() 指令会在后期讲到)。 - 子进程会继承父进程的部分属性(如环境变量、文件描述符等)。
- 新进程(子进程)通常由现有进程(父进程)通过
- 资源管理
- 父进程负责回收子进程的资源(避免僵尸进程)。
- 进程间关系维护
- 操作系统通过父子关系形成进程树(如
pstree命令显示的层级结构)。
- 操作系统通过父子关系形成进程树(如
这里只需要你有一个父进程的概念,你就可以理解成校长管理学生,而最上层对学生的管理你可以理解成教育局,教育局不可能实时关系每一个学生,
因此教育局就让每个学校有一个校长来管理学生,而校长也不可能管理那么多学生,故校长又让许多的辅导员来管理学生,而 Linux 中的进程管理
使用的也是这样的分层管理
我们通过查看该进程的父进程 id 对应信息会发现,该进程号对应的进程名叫 zsh:
╭─ljx@VM-16-15-debian ~/linux_review/lesson1/dir
╰─➤ ps axj | head -1 && ps axj | grep 1674011 130 ↵
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
1674010 1674011 1674011 1673035 pts/0 1765978 S 1003 0:06 zsh
1674011 1765978 1765978 1673035 pts/0 1765978 R+ 1003 0:00 ps axj
1674011 1765979 1765978 1673035 pts/0 1765978 S+ 1003 0:00 grep --color=auto --exclude-dir=.bzr --exclude-dir=CVS --exclude-dir=.git --exclude-dir=.hg --exclude-dir=.svn --exclude-dir=.idea --exclude-dir=.tox --exclude-dir=.venv --exclude-dir=venv 1674011这里需要说明一下,Linux 默认的 shell 是 bash 而不是 zsh,bash 是 Linux 中默认的命令行解析工具,所有的命令都会通过该命令解析然后创建对应的子进程并调用它们,
没错,Linux 中的 shell 是可以自由修改的,我为了有一个更好看的 shell 样式所以使用了 zsh 来配置主题,这也就解释了为什么该进程的父进程从来都没有改变,
原因就是该进程的父进程 zsh 一直都处于运行状态,而我们在命令行中输入的数据正是 zsh(或bash等其他shell)从标准输入中读取数据,我们按回车后 zsh 就会解析这个命令
并创建出子进程运行
因此,下面我们将要介绍子进程创建的一个工具:
fork
该命令用于创建子进程,首先我们看一下这个指令在 manual 中的定义:
fork(2) System Calls Manual fork(2)
NAME
fork - create a child process
LIBRARY
Standard C library (libc, -lc)
SYNOPSIS
#include <unistd.h>
pid_t fork(void);
DESCRIPTION
fork() creates a new process by duplicating the calling process. The
new process is referred to as the child process. The calling process is
referred to as the parent process.
......(话太多了这里只把目前需要的部分显示出来)
RETURN VALUE
On success, the PID of the child process is returned in the parent, and
0 is returned in the child. On failure, -1 is returned in the parent,
no child process is created, and errno is set to indicate the error. 可以看到,这个指令的返回值有两个,对于子进程,若进程创建成功则返回0,对于父进程,若进程创建成功则返回新创建的子进程的 pid,否则返回 -1
这里你肯定就会疑惑了,为什么一个函数可以返回两个返回值,还可以保证两个返回值不同
首先,创建的子进程是会继承父进程的代码的,他会和父进程一起并行执行代码,而 fork 函数返回返回值也是代码的一部分,因此父子进程在运行时就都可以通过 fork 函数
得到返回值,这样一来就很容易根据进程的不同得到不同的返回值了
那么,为什么父进程得到的返回值时子进程的 pid,而子进程得到的返回值时0或1呢?
这是为了在 fork 函数执行后更好的分流,进程执行后可以通过fork的返回值判断,若是0则说明时子进程,父进程则判断若是-1说明进程创建失败了,否则就成狗
至于是怎么实现返回两个不同的返回值的,这就涉及到了进程地址空间的讲解,我将在后面章节对他们进行一个讲解
下面时该指令使用的一个示例:
#include <iostream>
#include <unistd.h>
#include <sys/wait.h> // 添加 wait 相关头文件
using namespace std;
int main() {
int pid = fork();
if (pid == 0) {
// 子进程
cout << "I am child process, my pid is " << getpid()
<< " my ppid is " << getppid() << endl;
return 0;
} else {
// 父进程
cout << "I am parent process, my pid is " << getpid() << endl;
// 这里是为了等待子进程退出从而回收子进程的,否则子进程会变成孤儿进程(这个目前只需要了解,后面在讲进程状态时会重点讨论)
wait(nullptr); // 等待任意子进程退出
return 0;
}
}
执行后可以看到:
╭─ljx@VM-16-15-debian ~/linux_review/lesson1/dir1
╰─➤ ./test.o
I am parent process, my pid is 1778506
I am child process, my pid is 1778507 my ppid is 1778506子进程的 ppid 正好就是父进程的 pid,效果与预期相同