
Redis 常见数据类型-List 类型
类型简介
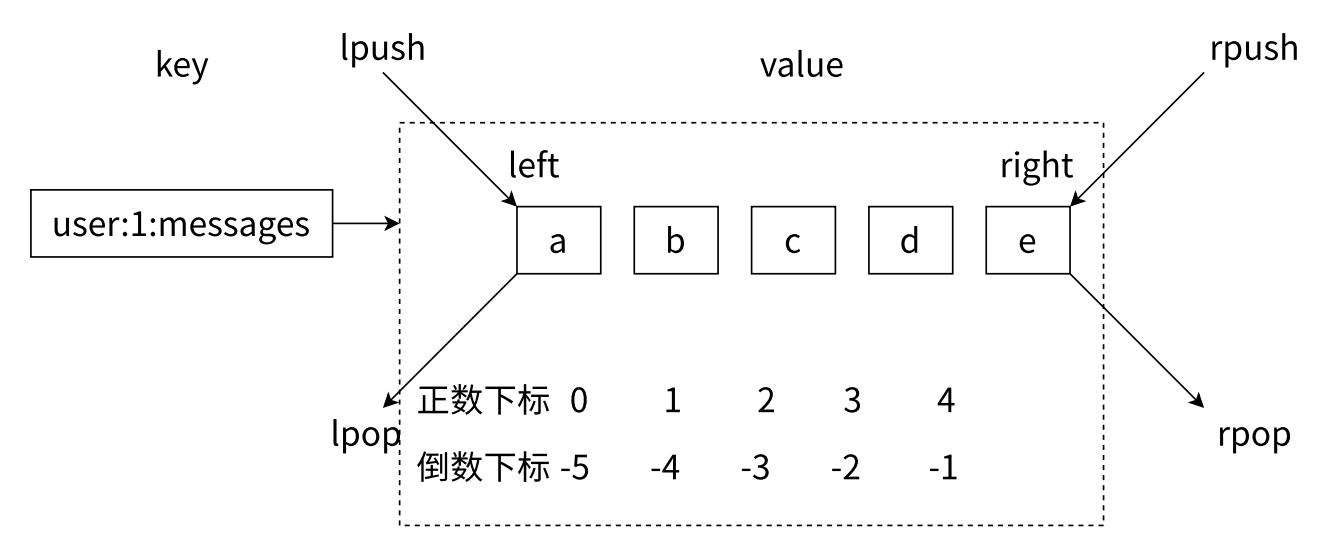
列表类型是⽤来存储多个有序的字符串,如图1所⽰,a、b、c、d、e 五个元素从左到右组成了⼀个有序的列表,列表中的每个
字符串称为元素(element),⼀个列表最多可以存储 2 − 32 1 个元素。在 Redis 中,可以对列表两端插⼊(push)和弹出(pop),
还可以获取指定范围的元素列表、获取指定索引下标的元素等(如图1和图2所⽰)。列表是⼀种⽐较灵活的数据结构,它可以
充当栈和队列的⻆⾊,在实际开发上有很多应⽤场景
列表类型的特点:
第⼀、列表中的元素是有序的,这意味着可以通过索引下标获取某个元素或者某个范围的元素列表,
例如要获取图 1 的第 5 个元素,可以执⾏ lindex user:1:messages 4 或者倒数第 1 个元素,lindex
user:1:messages -1 就可以得到元素 e。
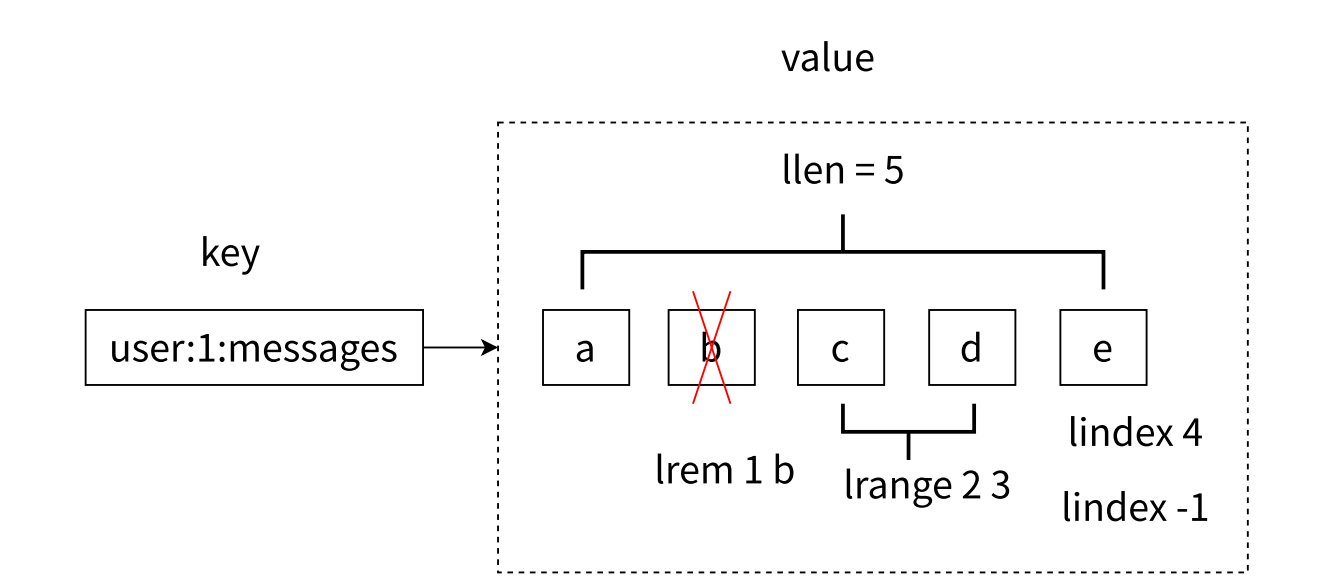
第⼆、区分获取和删除的区别,例如图2中的 lrem 1 b 是从列表中把从左数遇到的前 1 个 b 元素删
除,这个操作会导致列表的⻓度从 5 变成 4;但是执⾏ lindex 4 只会获取元素,但列表⻓度是不会变化
的。
第三、列表中的元素是允许重复的,例如图2中的列表中是包含了两个 a 元素的。
列表两端插入和弹出操作概念图(图1):
列表的获取、删除等操作概念图(图2):
相关指令
lpush
该指令用于将⼀个或者多个元素从左侧放⼊(头插)到 list 中
语法格式如下:
LPUSH key element [element ...]时间复杂度:只插⼊⼀个元素为 O(1), 插⼊多个元素为 O(N), N 为插⼊元素个数
返回值:插⼊后 list 的⻓度
使用示例:
127.0.0.1:6379> lpush k1 1 2 3 4
(integer) 4
127.0.0.1:6379> lpush k1 5 6 7 8
(integer) 8
# list 范围查询指令,后面会讲到,这里用于查询整个 list 的数据
127.0.0.1:6379> lrange k1 0 -1
1) "8"
2) "7"
3) "6"
4) "5"
5) "4"
6) "3"
7) "2"
8) "1"需要注意的是每个 value 前面的序号并不是下标,只是起到序号的作用,用来表示第几个数据
lrange
为了方便讲解,这里先将 lrange 指令介绍一下:
该指令用于获取从 start 到 end 区间的所有元素,左闭右闭,下表可以用负数表示,表示倒数第几个数据
时间复杂度:O(N)
返回值:指定区间的元素
针对不合法范围的处理
(1) 索引超出实际范围
Redis 会 自动修正为最接近的有效索引:
如果 start 超出列表右边界(start >= N),返回空列表 []。
如果 end 超出列表右边界(end >= N),自动修正为 N-1(列表最后一个元素)。
如果 start 超出左边界(start < -N),自动修正为 0(第一个元素)。
示例:
# 列表: ["a", "b", "c", "d", "e"](索引 0~4)
127.0.0.1:6379> LRANGE mylist 10 15
(empty array) # start >= N,返回空列表
127.0.0.1:6379> LRANGE mylist 2 100
1) "c" # end 超出,修正为 N-1=4
2) "d"
3) "e"(2) start > end
直接返回空列表 [],因为范围无效。
示例:
127.0.0.1:6379> LRANGE mylist 3 1
(empty array)(3) 负数索引
负数索引是合法的,表示从列表末尾开始计算(-1 是最后一个元素,-2 是倒数第二个,依此类推)。
如果负数索引超出左边界(如 -100),会修正为 0。
示例:
127.0.0.1:6379> LRANGE mylist -3 -1 # 最后三个元素
1) "c"
2) "d"
3) "e"
127.0.0.1:6379> LRANGE mylist -100 2 # start 超出左边界,修正为 0
1) "a"
2) "b"
3) "c"总结如下:
| 场景 | Redis 行为 | 示例(列表长度=5) |
|---|---|---|
start 超出右边界 |
返回空列表 [] |
LRANGE key 10 15 → [] |
end 超出右边界 |
修正为 N-1 |
LRANGE key 2 100 → [c,d,e] |
start 超出左边界 |
修正为 0 |
LRANGE key -100 1 → [a,b] |
start > end |
返回空列表 [] |
LRANGE key 3 1 → [] |
| 负数索引合法 | 正常返回对应元素 | LRANGE key -2 -1 → [d,e] |
当然,这种范围不合法的处理方式太过柔性,导致程序猿很难检查出问题,因此在编程时建议采用防御性编程,在代码中显式检查索引范围,避免依赖 Redis 的自动修正。
下面是针对 Redis 不合法访问处理的讨论
Redis 采用 柔性修正(自动调整非法范围为合法范围)的设计,主要基于以下几个核心考虑,尽管它可能增加调试难度,但整体上利大于弊:
- 设计哲学:简单性与容错性
减少用户的心智负担
Redis 的设计目标之一是 “简单、直观”。柔性修正让用户无需预先检查列表长度或计算精确的索引范围,尤其适合快速原型开发或脚本场景。- 示例:
LRANGE mylist 0 100直接返回所有元素,而不需要先调用LLEN查询长度。
- 示例:
符合自然直觉
类似 Python 的切片操作(如list[10:20]超出范围时返回空列表),Redis 的行为符合大多数开发者对”范围操作”的预期。
- 性能优化
减少往返操作(Round Trips)
如果强制要求索引严格合法,用户必须 先查询列表长度(LLEN),再计算有效范围,这会增加一次网络请求,降低性能(尤其在分布式环境中)。- 对比:柔性修正允许用户直接发起
LRANGE,由 Redis 内部处理边界。
- 对比:柔性修正允许用户直接发起
降低计算开销
Redis 是单线程模型,避免额外的LLEN查询能减少 CPU 和内存压力。
- 实际应用场景的需求
动态变化的列表
列表长度可能随时变化(如消息队列),柔性修正能保证命令 始终有确定的行为,而非因并发修改抛出错误。- 示例:在
LRANGE执行瞬间,列表被其他客户端缩短,修正机制仍能安全返回部分数据。
- 示例:在
批量处理的友好性
在分页查询等场景中,用户可能用固定步长(如每次查 10 条),柔性修正避免因最后一页不足 10 条而报错。
- 调试问题的权衡
虽然柔性修正可能掩盖某些错误,但 Redis 通过其他方式降低调试难度:
- 显式返回空列表
当start > end或start超出右边界时返回[],这是一种明确的”无数据”信号,而非隐式忽略错误。 - 文档清晰说明行为
Redis 官方文档 明确描述了索引超界时的修正逻辑,减少歧义。
- 对比其他数据库的设计
| 系统 | 范围处理策略 | 优缺点 |
|---|---|---|
| Redis | 柔性修正(自动调整) | 简单高效,但需注意边界逻辑 |
| SQL | 严格报错(如 OFFSET 超限) |
更精确,但需要额外处理错误 |
| Python | 切片自动调整 | 类似 Redis,符合开发者直觉 |
如何避免潜在问题?
- 代码层面防御
在业务逻辑中显式检查范围合法性(如先LLEN),而非依赖 Redis 修正。
list_len = redis.llen(key)
start = max(0, min(start, list_len - 1))
end = min(end, list_len - 1)监控与日志
对频繁返回空列表的LRANGE操作打日志,帮助发现潜在逻辑错误。使用 Lua 脚本
在脚本中封装严格的索引检查逻辑,保持原子性。
总结
Redis 选择柔性修正的核心原因是 在性能、简单性和实用性之间取得平衡。虽然可能增加调试复杂度,但通过良好的代码规范和文档学习,可以规避大部分问题。这种设计符合 Redis 作为 高性能、轻量级缓存/队列 的定位,而非强一致性的关系型数据库。
lpushx
在key 存在时,将⼀个或者多个元素从左侧放⼊(头插)到 list 中。不存在,直接返回
时间复杂度:只插⼊—个元素为 O(1), 插⼊多个元素为 O(N), N 为插⼊元素个数
返回值:插⼊后 list 的⻓度
语法格式如下:
LPUSHX key element [element ...]使用示例:
# k1 不存在,故无法 push
127.0.0.1:6379> lpushx k1 1 2 3 4
(integer) 0
# 可通过 lpush 创建新的 list
127.0.0.1:6379> lpush k1 1 2 3 4
(integer) 4
# lpush 创建后 list k1 存在,可利用 lpushx 继续插入新值
127.0.0.1:6379> lpushx k1 5 6 7 8
(integer) 8
# 查看被插入 list 的元素
127.0.0.1:6379> lrange k1 0 -1
1) "8"
2) "7"
3) "6"
4) "5"
5) "4"
6) "3"
7) "2"
8) "1"rpush、rpushx
用法和 lpush 和 lpushx 相同,只不过变成了尾插,这里不再过多赘述
下面是使用示例:
# 直接使用 rpushx 插入不存在的 list 失败
127.0.0.1:6379> rpushx k1 1 2 3 4
(integer) 0
# 先用 rpush 创建新的 list
127.0.0.1:6379> rpush k1 1 2 3 4
(integer) 4
# 再用 rpushx 插入新值成功
127.0.0.1:6379> rpushx k1 5 6 7 8
(integer) 8
# 查看 k1 中所有的元素
127.0.0.1:6379> lrange k1 0 -1
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
8) "8"lpop、rpop
lpop 指令用于从 list 左侧取出元素(即头删)
rpop 指令用于从 list 右侧取出元素(即尾删)
时间复杂度:O(1)
语法格式:
LPOP key
RPOP key返回值:取出的元素或者 nil。
下面是使用示例:
127.0.0.1:6379> rpush k1 1 2 3 4
(integer) 4
# 当前 list 中元素为 {1,2,3,4}
127.0.0.1:6379> lrange k1 0 -1
1) "1"
2) "2"
3) "3"
4) "4"
# 头删获得元素1
127.0.0.1:6379> lpop k1
"1"
# 尾删获得元素4
127.0.0.1:6379> rpop k1
"4"
127.0.0.1:6379> lrange k1 0 -1
1) "2"
2) "3"
127.0.0.1:6379> rpop k1
"3"
127.0.0.1:6379> rpop k1
"2"
# list 中所有元素都被取完了,返回 nil
127.0.0.1:6379> rpop k1
(nil)lindex
该指令用于获取从左数第 index 位置的元素
语法如下:
LINDEX key index时间复杂度:O(N)
返回值:取出的元素或者 nil
使用示例:
# 插入元素 1 2 3 4 到 list k1 中
127.0.0.1:6379> rpush k1 1 2 3 4
(integer) 4
# 获取下标为 3 的元素
127.0.0.1:6379> lindex k1 3
"4"
# 获取下标为 0 的元素
127.0.0.1:6379> lindex k1 0
"1"
# 支持负数下标访问(表示获取倒数第几个元素)
127.0.0.1:6379> lindex k1 -1
"4"
# 越界访问返回 nil
127.0.0.1:6379> lindex k1 6
(nil)
# 负数越界同理
127.0.0.1:6379> lindex k1 -5
(nil)linsert
该指令用于在特定位置插⼊元素
语法如下:
LINSERT key <BEFORE | AFTER> pivot element时间复杂度:O(N)
返回值:插⼊后的 list ⻓度
使用示例:
# 生成一个新的 list 插入 1
127.0.0.1:6379> lpush k1 1
(integer) 1
# 在元素 1 的前面插入 2
127.0.0.1:6379> linsert k1 before 1 2
(integer) 2
# 在元素 2 的后面插入 3
127.0.0.1:6379> linsert k1 after 1 3
(integer) 3
# 查看插入是否符合预期
127.0.0.1:6379> lrange k1 0 -1
1) "2"
2) "1"
3) "3"lrem
该指令用于删除前指定个数的元素
时间复杂度:O(N)
返回值:被成功删除的元素个数
指令格式如下:
LREM key count element使用示例如下:
127.0.0.1:6379> rpush k1 1 2 3 4 4 4 5 6 7 4 4 4
(integer) 12
# 尝试删除4个2,但因为只有一个故返回1
127.0.0.1:6379> lrem k1 4 2
(integer) 1
127.0.0.1:6379> lrange k1 0 -1
1) "1"
2) "3"
3) "4"
4) "4"
5) "4"
6) "5"
7) "6"
8) "7"
9) "4"
10) "4"
11) "4"
# 尝试删除2个4,成功将前面两个4给删除了
127.0.0.1:6379> lrem k1 2 4
(integer) 2
127.0.0.1:6379> lrange k1 0 -1
1) "1"
2) "3"
3) "4"
4) "5"
5) "6"
6) "7"
7) "4"
8) "4"
9) "4"llen
该指令用于获取 list 的长度
语法如下:
LLEN key时间复杂度:O(1)
返回值:list 的⻓度
使用示例如下:
# 创建一个长度为 4 的 list
127.0.0.1:6379> lpush k1 1 2 3 4
(integer) 4
# 查看长度
127.0.0.1:6379> llen k1
(integer) 4
# 查看不存在的 list 的长度
127.0.0.1:6379> llen k2
(integer) 0
# 创建一个 非 list 的 k2
127.0.0.1:6379> hset k2 f1 v1
(integer) 1
# 因类型不匹配报错
127.0.0.1:6379> llen k2
(error) WRONGTYPE Operation against a key holding the wrong kind of value阻塞版本指令
Redis 阻塞列表操作:BLPOP 和 BRPOP
BLPOP 和 BRPOP 是 LPOP 和 RPOP 的阻塞版本,它们的基本功能与非阻塞版本类似,但有以下关键区别:
主要特性
阻塞行为
- 有元素时:行为与非阻塞版本一致。
- 无元素时:
- 非阻塞版本会立即返回
nil。 - 阻塞版本会根据
timeout参数阻塞一段时间(期间 Redis 可处理其他命令,但客户端表现为阻塞状态。
- 非阻塞版本会立即返回
多键操作
- 如果命令中设置了多个键,会按从左到右顺序遍历键列表,一旦某个键对应的列表可弹出元素,命令立即返回。
并发竞争
- 多个客户端同时对同一个键执行阻塞弹出操作时,最先执行命令的客户端会成功获取元素。
1. 时序图:客户端与 Redis 的交互过程
场景1:列表不为空时
sequenceDiagram
participant Client
participant Redis
Note over Redis: user:1:messages = [x, z, y]
Client->>Redis: LPOP user:1:messages
Redis-->>Client: x
Client->>Redis: BLPOP user:1:messages 5
Redis-->>Client: x
Note left of Redis: 有元素时行为完全一致
场景2:空列表且无新元素(5秒超时)
sequenceDiagram
participant Client
participant Redis
Note over Redis: user:1:messages = []
Client->>Redis: LPOP user:1:messages
Redis-->>Client: nil (立即)
Client->>Redis: BLPOP user:1:messages 5
loop 5秒检查
Redis->>Redis: 检查列表
end
Redis-->>Client: nil (5秒后)
Note left of Redis: 无元素时LPOP立即返回,
BLPOP阻塞等待
场景3:空列表但5秒内加入新元素
sequenceDiagram
participant ClientA
participant ClientB
participant Redis
Note over Redis: user:1:messages = []
ClientA->>Redis: LPOP user:1:messages
Redis-->>ClientA: nil (立即)
par 并行事件
ClientA->>Redis: BLPOP user:1:messages 5
and
ClientB->>Redis: LPUSH user:1:messages x
Redis-->>ClientA: x (中断等待)
end
Note right of ClientB: BLPOP在等待期间
捕获到新元素
2. 流程图:操作逻辑对比
flowchart TD
A[开始] --> B{列表是否为空?}
B -- 否 --> C[LPOP/BLPOP弹出首元素]
B -- 是 --> D{操作类型}
D -- LPOP --> E[立即返回nil]
D -- BLPOP --> F[启动超时计时器]
F --> G{期间有新元素?}
G -- 是 --> H[立即返回新元素]
G -- 否 --> I[超时后返回nil]
style C fill:#d4edda,stroke:#28a745
style E fill:#f8d7da,stroke:#dc3545
style H fill:#d4edda,stroke:#28a745
style I fill:#fff3cd,stroke:#ffc107
关键结论
| 场景 | LPOP (非阻塞) | BLPOP (阻塞) |
|---|---|---|
| 列表有元素 | 立即返回元素 | 立即返回元素 |
| 空列表且无新元素 | 立即返回nil |
阻塞至超时后返回nil |
| 空列表但新元素到达 | 需再次调用才获取 | 在等待期内直接捕获新元素 |
下面只正对指令 blpop 进行讨论, brpop 同理
blpop 指令讲解
blpop 指令可以同时阻塞等待多个 list,当某个 list 中有元素则会取出该 list 中的元素并停止阻塞
语法格式:
BLPOP key [key ...] timeout使用示例:
场景1:等待一个 list
# 客户端 1 阻塞等待一个 list 最多 100s
127.0.0.1:6379> blpop k1 100
1) "k1"
2) "1"
(9.94s)
# 客户端 2 给 k1 头插元素 1
127.0.0.1:6379> lpush k1 1
(integer) 1场景2:等待多个 list
# 客户端 1 阻塞等待多个 list 最多 100s
127.0.0.1:6379> blpop k1 k2 k3 k4 100
1) "k3"
2) "100"
(5.52s)
# 客户端 2 给 k3 头插元素 1
127.0.0.1:6379> lpush k3 100
(integer) 1list 相关指令汇总表
| 操作类型 | 命令 | 时间复杂度 |
|---|---|---|
| 添加 | rpush key value [value ...] |
O(k),k 是元素个数 |
lpush key value [value ...] |
O(k),k 是元素个数 | |
linsert key before|after pivot value |
O(n),n 是 pivot 距离头尾的距离 | |
| 查找 | lrange key start end |
O(s+n),s 是 start 偏移量,n 是范围 |
lindex key index |
O(n),n 是索引的偏移量 | |
llen key |
O(1) | |
| 删除 | lpop key |
O(1) |
rpop key |
O(1) | |
lrem key count value |
O(k),k 是元素个数 | |
ltrim key start end |
O(k),k 是元素个数 | |
| 修改 | lset key index value |
O(n),n 是索引的偏移量 |
| 阻塞操作 | blpop brpop |
O(1) |
内部编码
Redis 列表类型的内部编码实现
Redis 列表类型的内部编码有两种,根据元素数量和大小自动选择:
内部编码类型
ziplist (压缩列表):
- 触发条件:
- 元素个数 <
list-max-ziplist-entries(默认 512) - 每个元素长度 <
list-max-ziplist-value(默认 64 字节)
- 元素个数 <
- 优点:内存连续存储,减少内存碎片
- 触发条件:
linkedlist (链表):
- 触发条件:不满足 ziplist 的任一条件时
- 特点:双向链表实现,适合存储大量或大元素数据
配置参数
# redis.conf 配置示例
list-max-ziplist-entries 512 # 最大元素个数阈值
list-max-ziplist-value 64 # 单个元素最大字节阈值示例演示
1. 使用 ziplist 编码(满足两个条件)
127.0.0.1:6379> RPUSH listkey e1 e2 e3
OK
127.0.0.1:6379> OBJECT ENCODING listkey
"ziplist"2. 元素数量超限转为 linkedlist
127.0.0.1:6379> RPUSH listkey e1 e2 ... e512 e513 # 插入513个元素
OK
127.0.0.1:6379> OBJECT ENCODING listkey
"linkedlist"3. 元素大小超限转为 linkedlist
127.0.0.1:6379> RPUSH listkey "超过64字节的长字符串XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
OK
127.0.0.1:6379> OBJECT ENCODING listkey
"linkedlist"性能建议
- 需要大量小元素存储时 → 保持默认 ziplist 配置
- 需要存储大元素时 → 适当调大
list-max-ziplist-value - 元素数量波动大时 → 可调整
list-max-ziplist-entries
典型业务场景
缓存功能
下面以学生列表为例展开说明:
数据结构设计
使用 Redis List 存储班级学生信息,每个班级对应一个 List,学生ID/姓名作为元素:
flowchart LR
classList["班级列表"] --> class1["class:1:students"]
classList --> class2["class:2:students"]
class1 -->|"元素"| stu1["stu_001"]
class1 -->|"元素"| stu2["stu_002"]
class1 -->|"..."| stun["stu_999"]
核心操作命令
1. 初始化班级学生列表
# 添加学生到班级1(尾部插入)
RPUSH class:1:students stu_001 stu_002 stu_003
# 添加学生到班级2(头部插入)
LPUSH class:2:students stu_101 stu_1022. 查询学生列表
sequenceDiagram
participant Client
participant Redis
Client->>Redis: LRANGE class:1:students 0 -1
Redis-->>Client: ["stu_001", "stu_002", "stu_003"]
# 获取班级1全部学生(0表示起始索引,-1表示末尾)
LRANGE class:1:students 0 -1
# 获取前5名学生
LRANGE class:1:students 0 43. 学生变动操作
gantt
title 学生名单变更流程
dateFormat YYYY-MM-DD
section 班级1
新生入学 :2023-09-01, 1d
学生转出 :2023-09-05, 1d
# 学生转入(尾部添加)
RPUSH class:1:students stu_004
# 学生转出(头部移除)
LPOP class:1:students
# 删除指定学生
LREM class:1:students 1 stu_002性能优化建议
| 场景 | 优化方案 | 命令示例 |
|---|---|---|
| 高频新增 | 使用 Pipeline 批量操作 | RPUSH + MULTI/EXEC |
| 大规模名单查询 | 分页获取 | LRANGE class:1 0 49 |
| 需要保证顺序 | 配合 SORT 命令 | SORT class:1 ALPHA |
| 防止重复 | 结合 SET 去重 | SADD class:1:set stu_001 |
完整示例流程
sequenceDiagram
participant Teacher
participant Redis
Note over Teacher: 新学期开始
Teacher->>Redis: RPUSH class:2023:students Alice Bob Charlie
Redis-->>Teacher: (integer) 3
Teacher->>Redis: LRANGE class:2023:students 0 -1
Redis-->>Teacher: 1) "Alice" 2) "Bob" 3) "Charlie"
Note over Teacher: 学生David转入
Teacher->>Redis: RPUSH class:2023:students David
Redis-->>Teacher: (integer) 4
Note over Teacher: 学生Bob转出
Teacher->>Redis: LREM class:2023:students 1 Bob
Redis-->>Teacher: (integer) 1
注意事项
- 当学生数量 > 512 或名字长度 > 64字节时,Redis 会自动将 ziplist 转为 linkedlist
- 重要数据建议持久化:
BGSAVE - 可配合 Hash 存储学生详细信息:
HMSET student:stu_001 name "Alice" age 12 gender F消息队列
1. 基础阻塞消息队列模型
sequenceDiagram
participant Producer
participant Redis as Redis Server
participant Consumer1
participant Consumer2
participant Consumer3
Note over Producer: 生产者客户端
Note over Consumer1,Consumer3: 消费者客户端集群
Producer->>Redis: LPUSH queue_msg "消息1"
loop BRPOP 阻塞等待
Consumer1->>Redis: BRPOP queue_msg 30
Consumer2->>Redis: BRPOP queue_msg 30
Consumer3->>Redis: BRPOP queue_msg 30
end
Redis-->>Consumer2: 返回"消息1" (只有一个消费者抢到)
实现方式:
- 生产者:
LPUSH key element [element...] - 消费者:
BRPOP key [key...] timeout - 特点:
- 自动阻塞等待
- 多消费者负载均衡
- 保证消息不重复消费
2. 分频道消息队列模型
flowchart TB
subgraph Redis服务器
queue1[(queue:1)]
queue2[(queue:2)]
queue3[(queue:3)]
end
Producer -->|LPUSH queue:1| queue1
Producer -->|LPUSH queue:2| queue2
Producer -->|LPUSH queue:3| queue3
queue1 --> ConsumerA(ConsumerA:
BRPOP queue:1)
queue1 --> ConsumerB(ConsumerB:
BRPOP queue:1)
queue1 --> ConsumerC(ConsumerC:
BRPOP queue:1,queue:2)
queue2 --> ConsumerC
queue2 --> ConsumerD(ConsumerD:
BRPOP queue:2,queue:3)
queue3 --> ConsumerD
频道订阅模式:
# 生产者发布消息到不同频道
LPUSH channel:news "最新消息"
LPUSH channel:alert "系统警报"
# 消费者订阅不同组合:
BRPOP channel:news 30 # 只订阅新闻频道
BRPOP channel:news channel:alert 30 # 多频道监听两种模型对比
| 特性 | 基础模型 | 分频道模型 |
|---|---|---|
| 消息类型 | 单一类型 | 多频道分类 |
| 消费者竞争范围 | 全局竞争 | 频道内竞争 |
| 命令示例 | BRPOP queue 30 |
BRPOP chan1 chan2 30 |
| 适用场景 | 单一业务流 | 多业务分类处理 |
| 吞吐量 | 所有消费者共享 | 分频道并行处理 |
Redis 实现微博 Timeline 方案
数据结构设计
flowchart LR
user1["user:1:mblogs"] --> mblog1["mblog:1"]
user1 --> mblog3["mblog:3"]
userk["user:k:mblogs"] --> mblog9["mblog:9"]
mblog1 -->|HASH| content1["title: xx\ntimestamp: 1476536196\ncontent: xxxxx"]
mblog3 -->|HASH| content3["title: yy\ntimestamp: 1476536197\ncontent: yyyyy"]
mblog9 -->|HASH| content9["title: zz\ntimestamp: 1476536198\ncontent: zzzzz"]
核心操作实现
1. 微博存储(Hash结构)
# 存储单篇微博
HMSET mblog:1 title "Redis实战" timestamp 1476536196 content "使用List实现Timeline..."
# 批量存储示例
MULTI
HMSET mblog:2 title "Redis优化" timestamp 1476536197 content "Pipeline使用技巧"
HMSET mblog:3 title "Mermaid教程" timestamp 1476536198 content "图表绘制指南"
EXEC2. Timeline更新(List操作)
sequenceDiagram
participant 客户端
participant Redis
客户端->>Redis: LPUSH user:1:mblogs mblog:1 mblog:3
Redis-->>客户端: (integer) 2
客户端->>Redis: LPUSH user:1:mblogs mblog:9
Redis-->>客户端: (integer) 3
3. 分页查询方案
# 获取第一页(10条)
LRANGE user:1:mblogs 0 9
--> ["mblog:9", "mblog:3", "mblog:1", ...]
# 配合Pipeline获取详情
MULTI
HGETALL mblog:9
HGETALL mblog:3
HGETALL mblog:1
EXEC性能优化方案
问题1:1+N 查询问题
| 方案 | 实现方式 | 优缺点对比 |
|---|---|---|
| Pipeline批量查询 | MULTI + HGETALL + EXEC |
减少网络往返,但代码复杂度增加 |
| 字符串序列化存储 | SET + MGET |
读取高效,但更新灵活性降低 |
问题2:中间元素访问性能
flowchart TB
subgraph 大列表拆分方案
original["user:1:mblogs (超大列表)"]
split1["user:1:mblogs:part1"]
split2["user:1:mblogs:part2"]
split3["user:1:mblogs:part3"]
end
拆分策略:
按时间分片:
user:<uid>:mblogs:<year-month>按数量分片:每1000条微博一个子列表
数据结构选型建议
| 操作模式 | 命令组合 | 适用场景 |
|---|---|---|
| 栈模式 | LPUSH + LPOP |
最新微博优先展示 |
| 队列模式 | LPUSH + RPOP |
时间线严格按序展示 |
| 双向存取 | LPUSH + BRPOP |
消息队列场景 |
生产环境注意事项
- 内存控制:
# 限制单个用户Timeline长度
LTRIM user:1:mblogs 0 999- 性能监控:
redis-cli --latency -h 127.0.0.1
INFO memory- 异常处理:
def get_timeline_page(uid, page, size=10):
try:
start = (page-1)*size
keys = redis.lrange(f"user:{uid}:mblogs", start, start+size-1)
return redis.pipeline().hgetall(*keys).execute()
except RedisError as e:
log_error(f"Timeline query failed: {e}")
return []